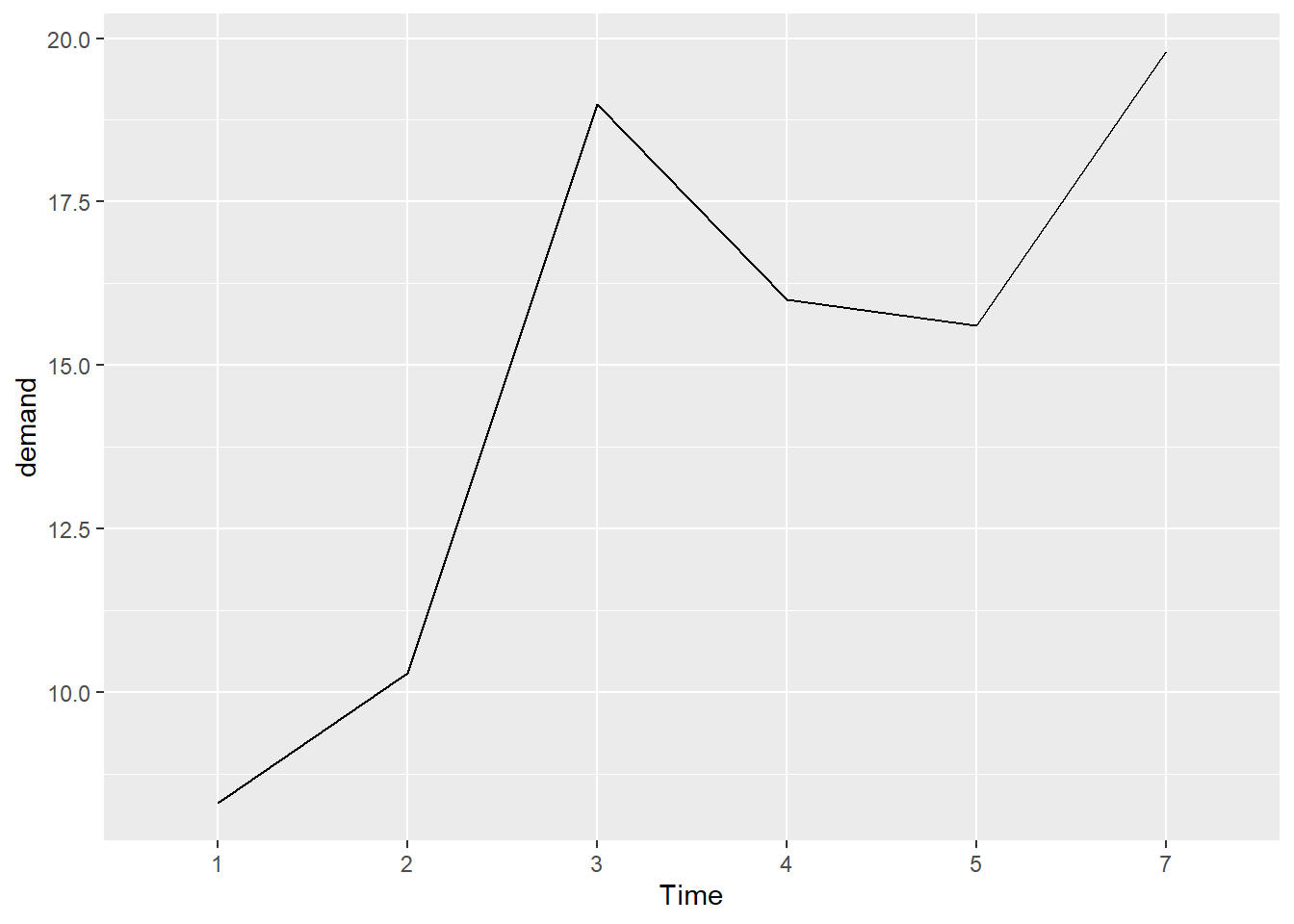
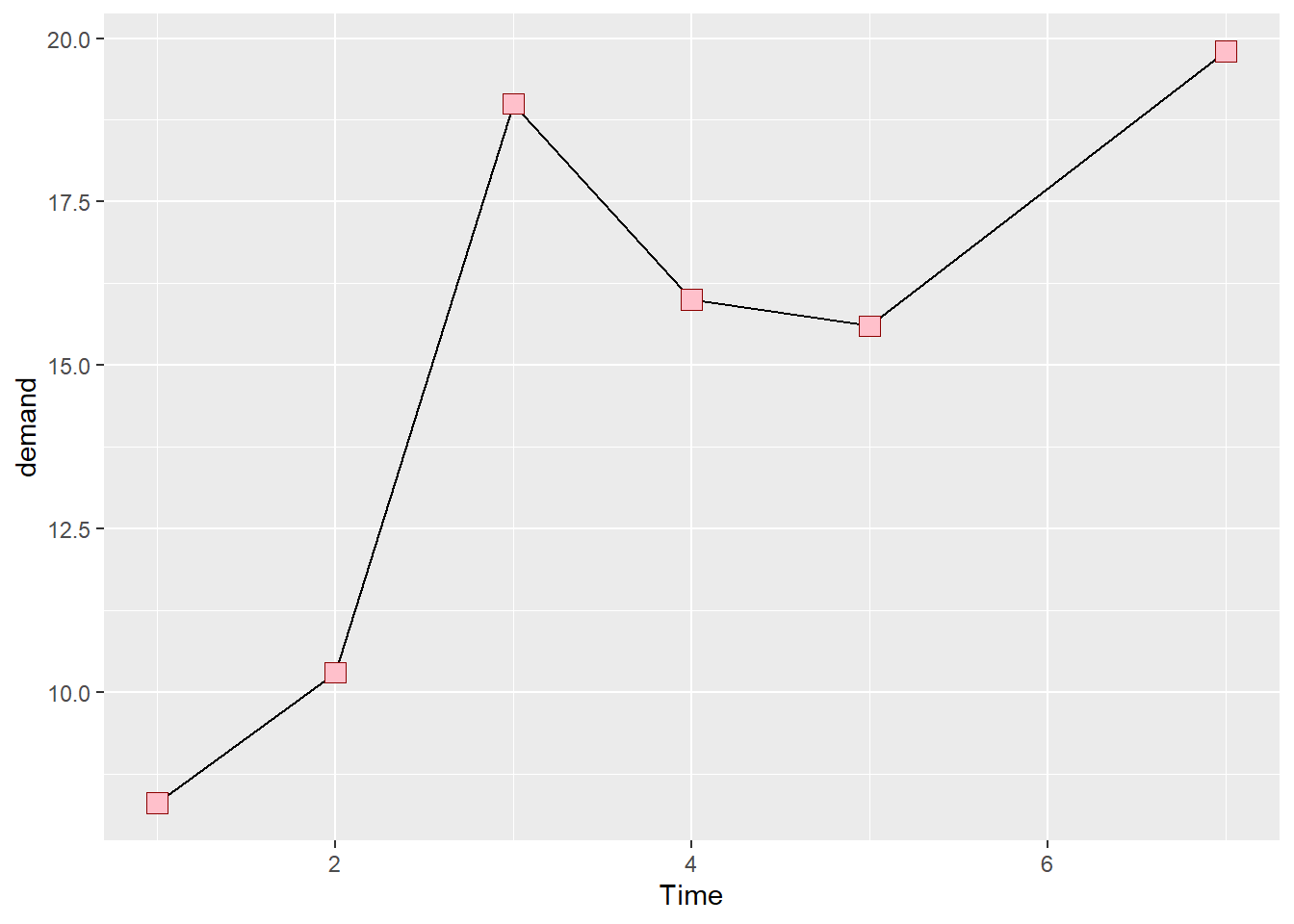
Time demand
1 1 8.3
2 2 10.3
3 3 19.0
4 4 16.0
5 5 15.6
6 7 19.8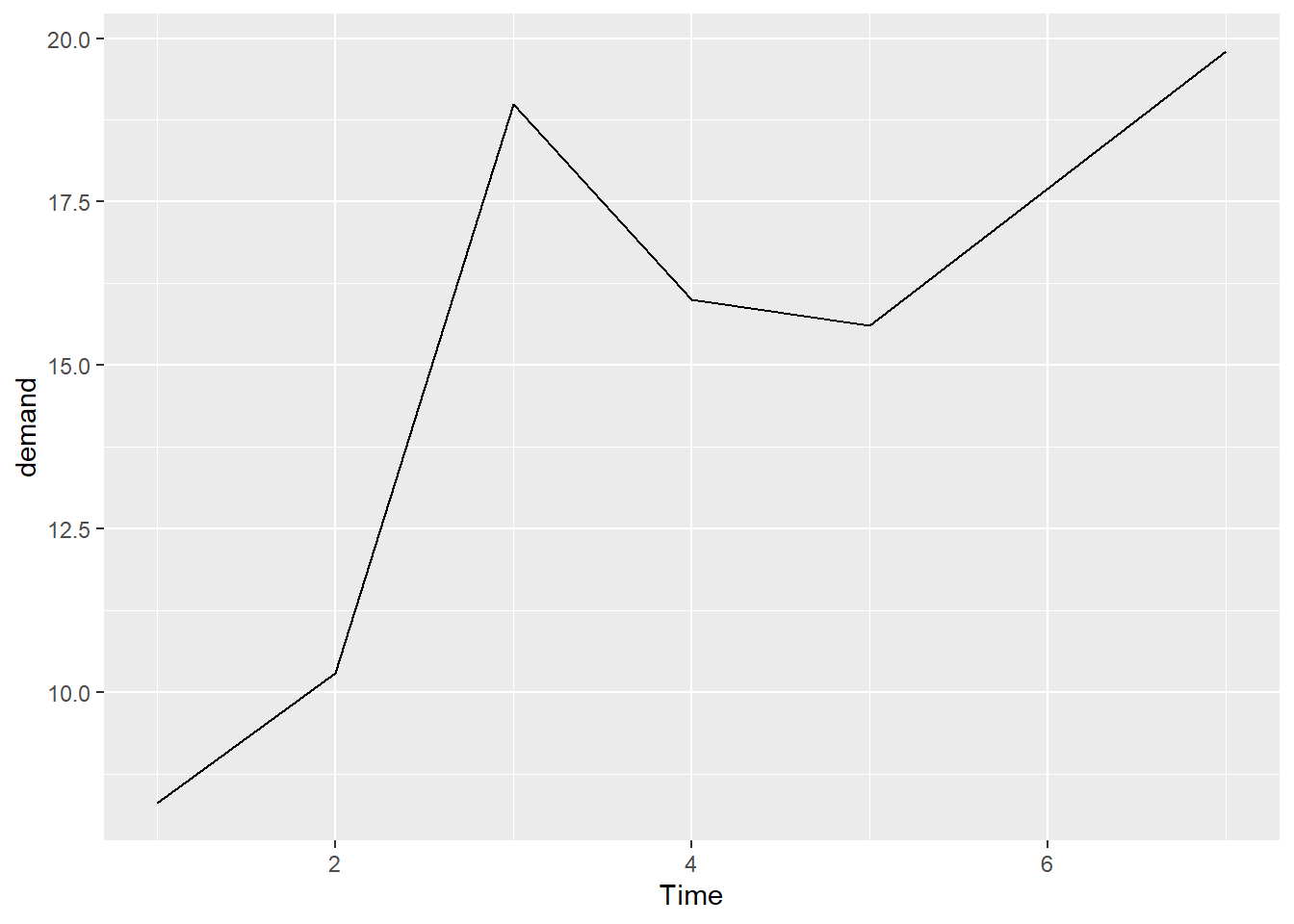
运行 ggplot() 函数和 geom_line() 函数,并分别指定一个变量映射到 x 和 y 。
Time demand
1 1 8.3
2 2 10.3
3 3 19.0
4 4 16.0
5 5 15.6
6 7 19.8折线图的 X 轴既可以对应于离散(分类)变量,也可以对应于连续(数值型)变量。
在上图中,Demand 变量为数值型变量,但我们可以借助于 factor() 函数将其转换为因子型变量,然后,将其当作分类变量来处理。
当 X 对应于因子型变量时,必须使用命令 aex(group = 1) 以确保 ggplot 知道这些数据点属于同一个分组,应该用一条折现将他们连在一起。
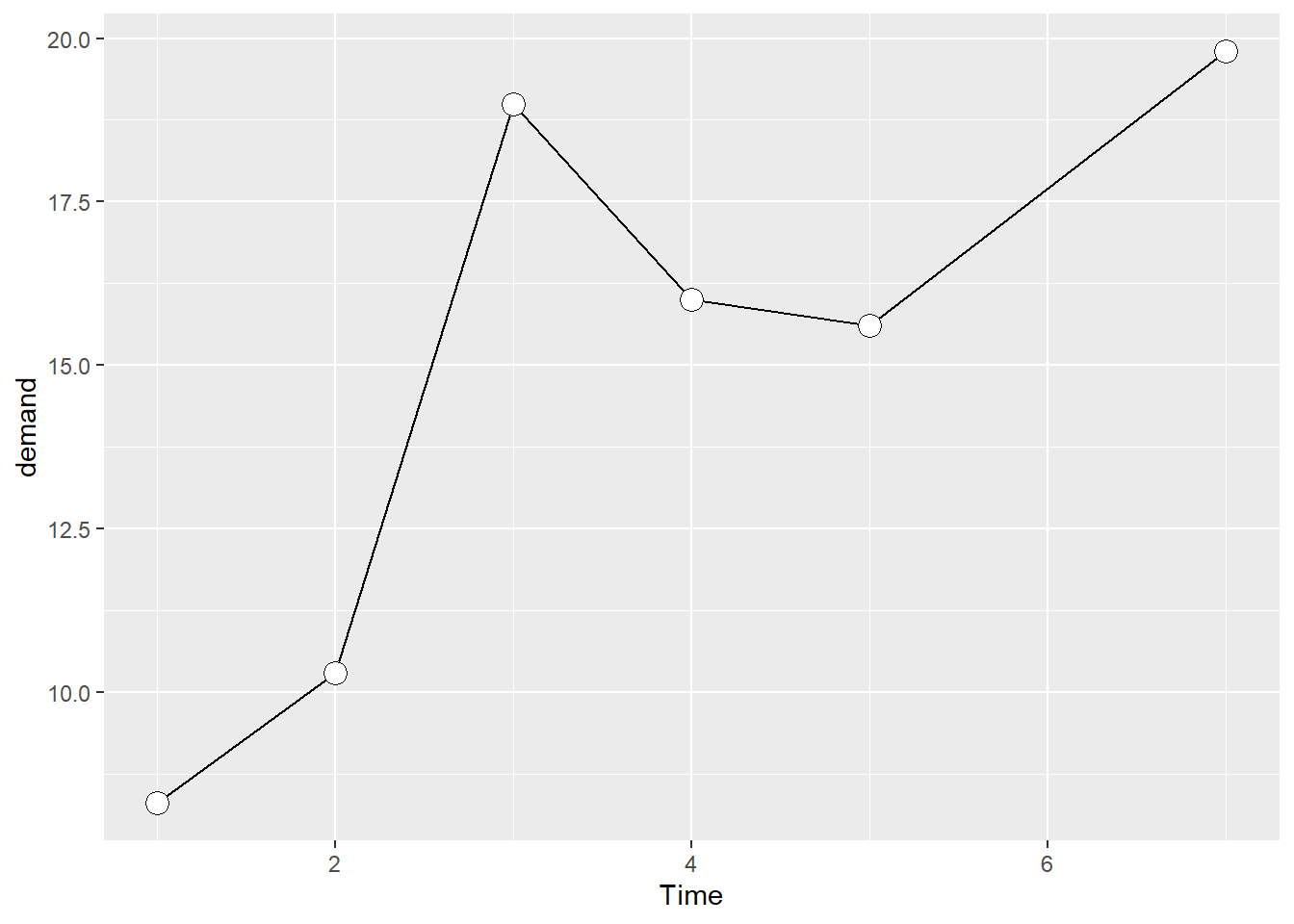
在代码中加上 geom_point() 即可:
Time demand
1 1 8.3
2 2 10.3
3 3 19.0
4 4 16.0
5 5 15.6
6 7 19.8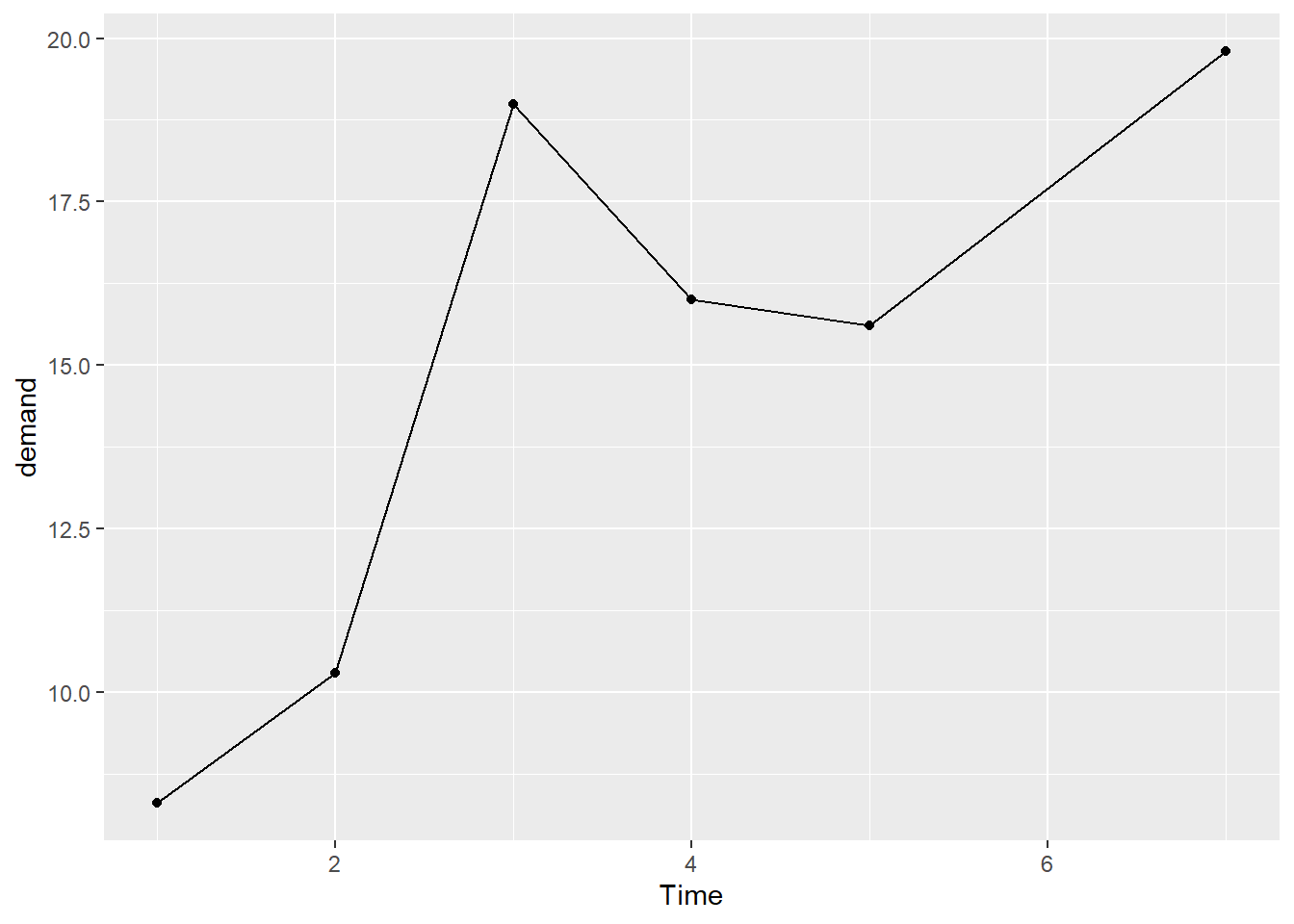
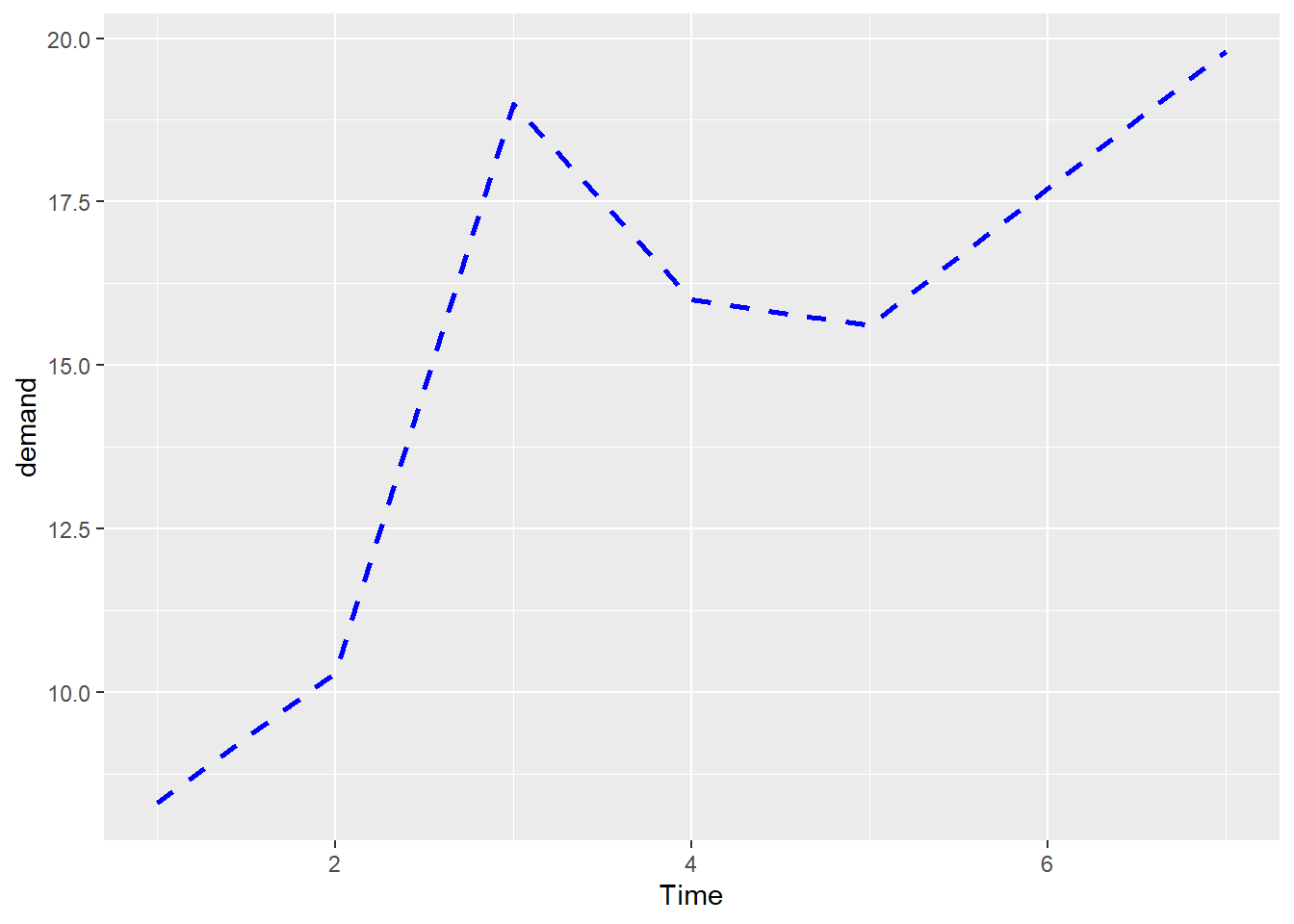
有时候,在折线图上添加数据标记很有用。
当数据点的密度较低或数据采集频率不规则时,尤其有用。
例如,BOD 数据集中没有与 Time=6 相对应的输入,然而,这在一张单独的折线图中看起来并不明显。
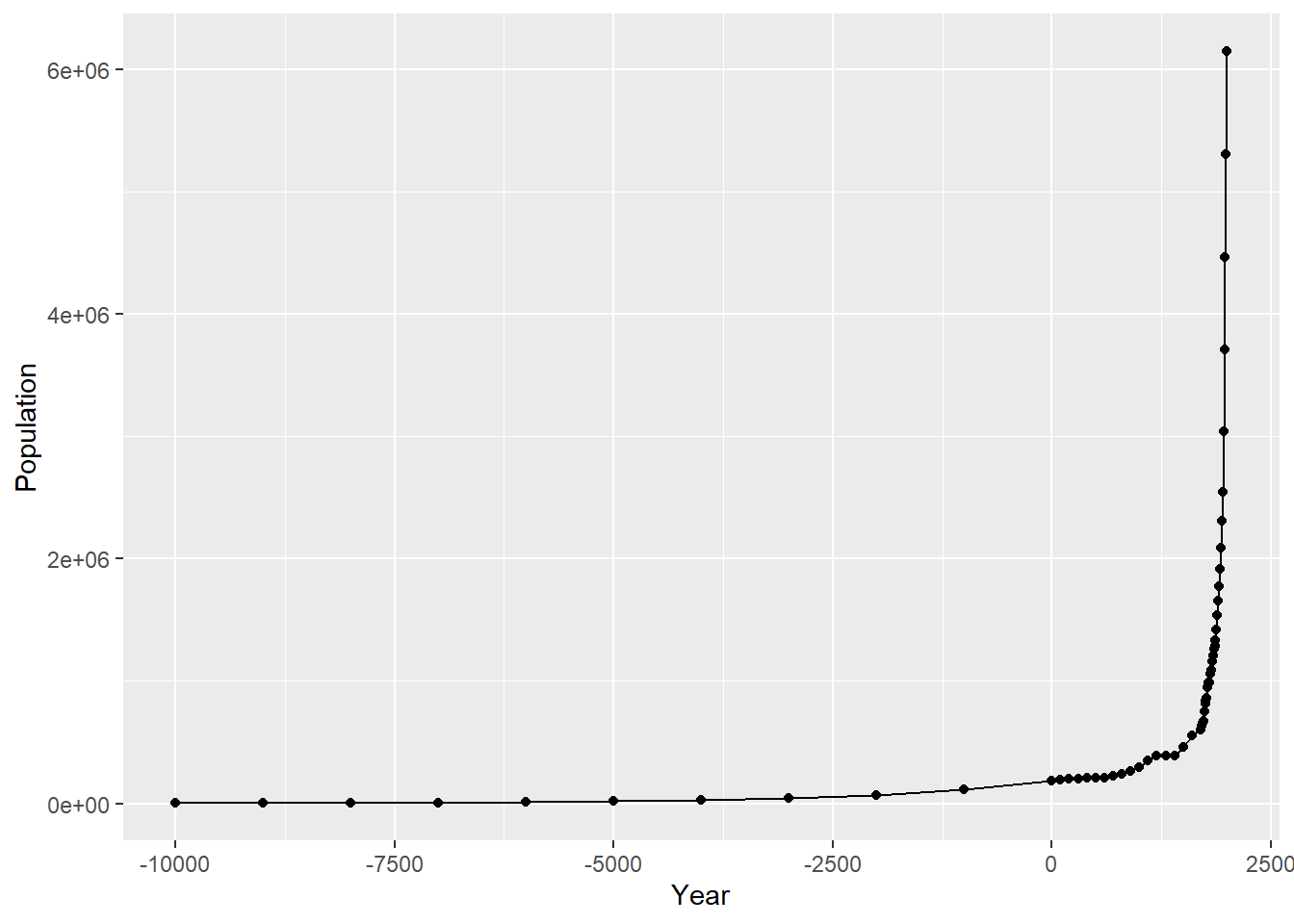
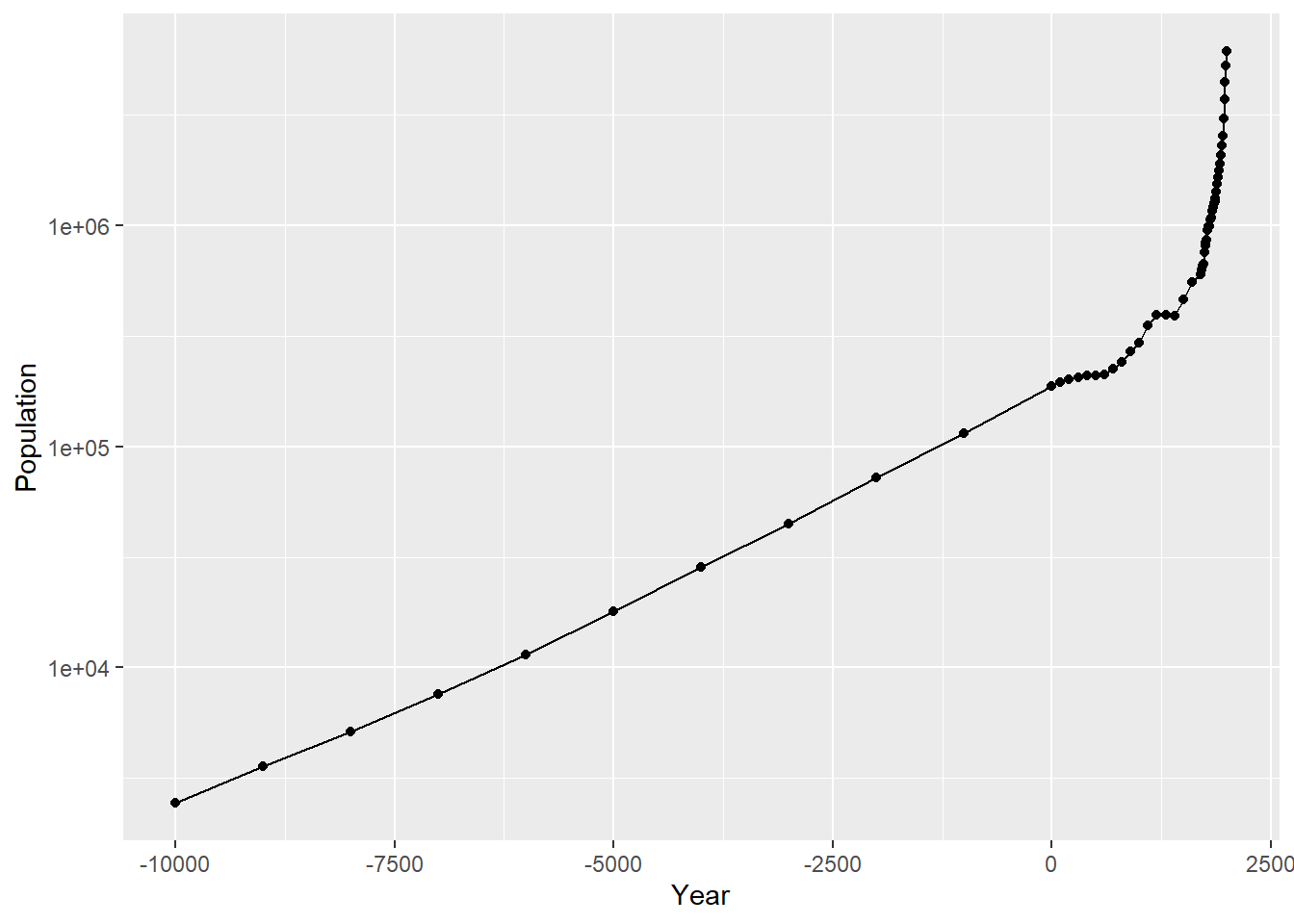
worldpop数据集对应的采集时间间隔不是常数,时间距今较久远的数据采集频率比新近不久的数据采集频率低。
折线图中的数据标记表明了数据的采集时间:
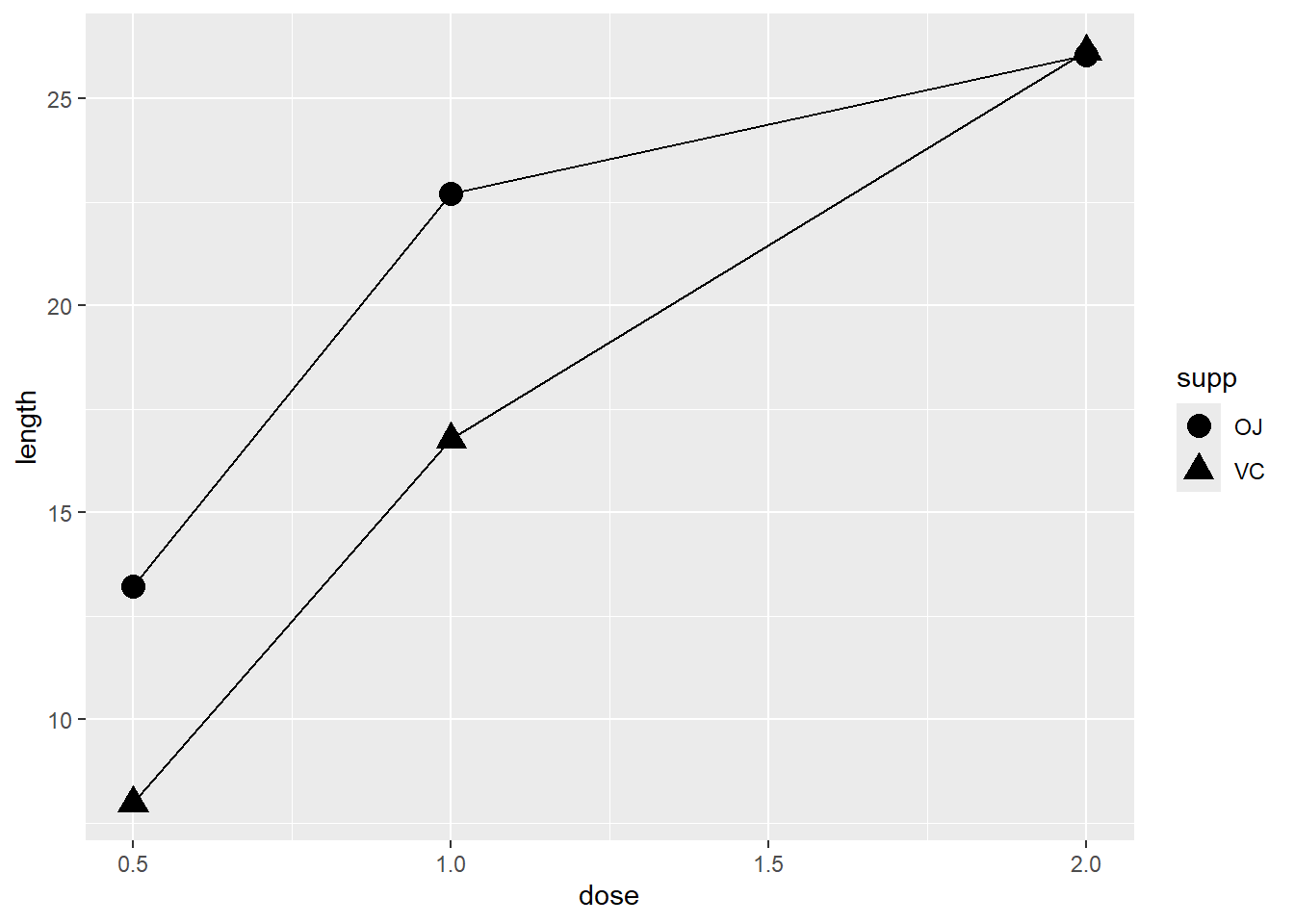
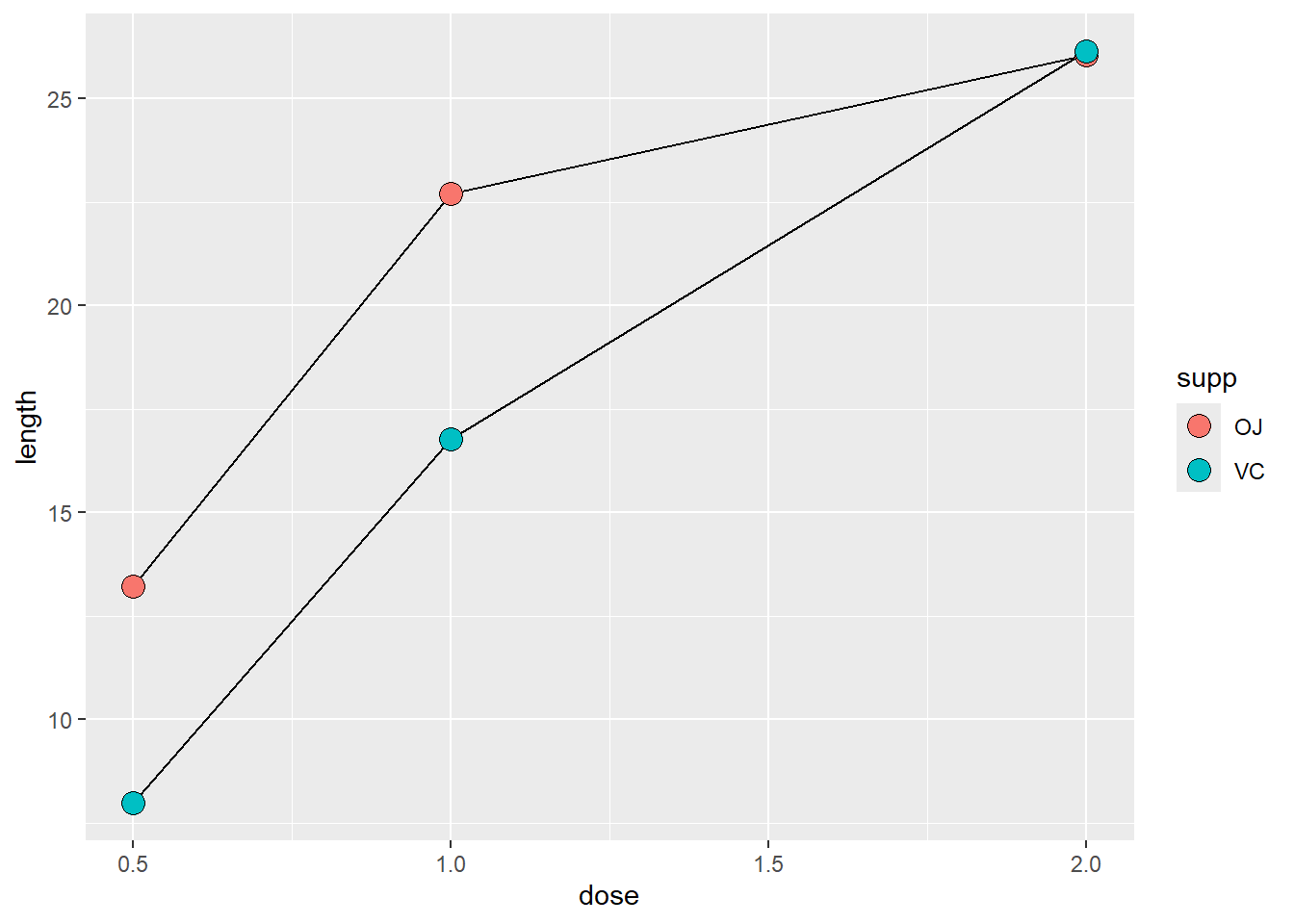
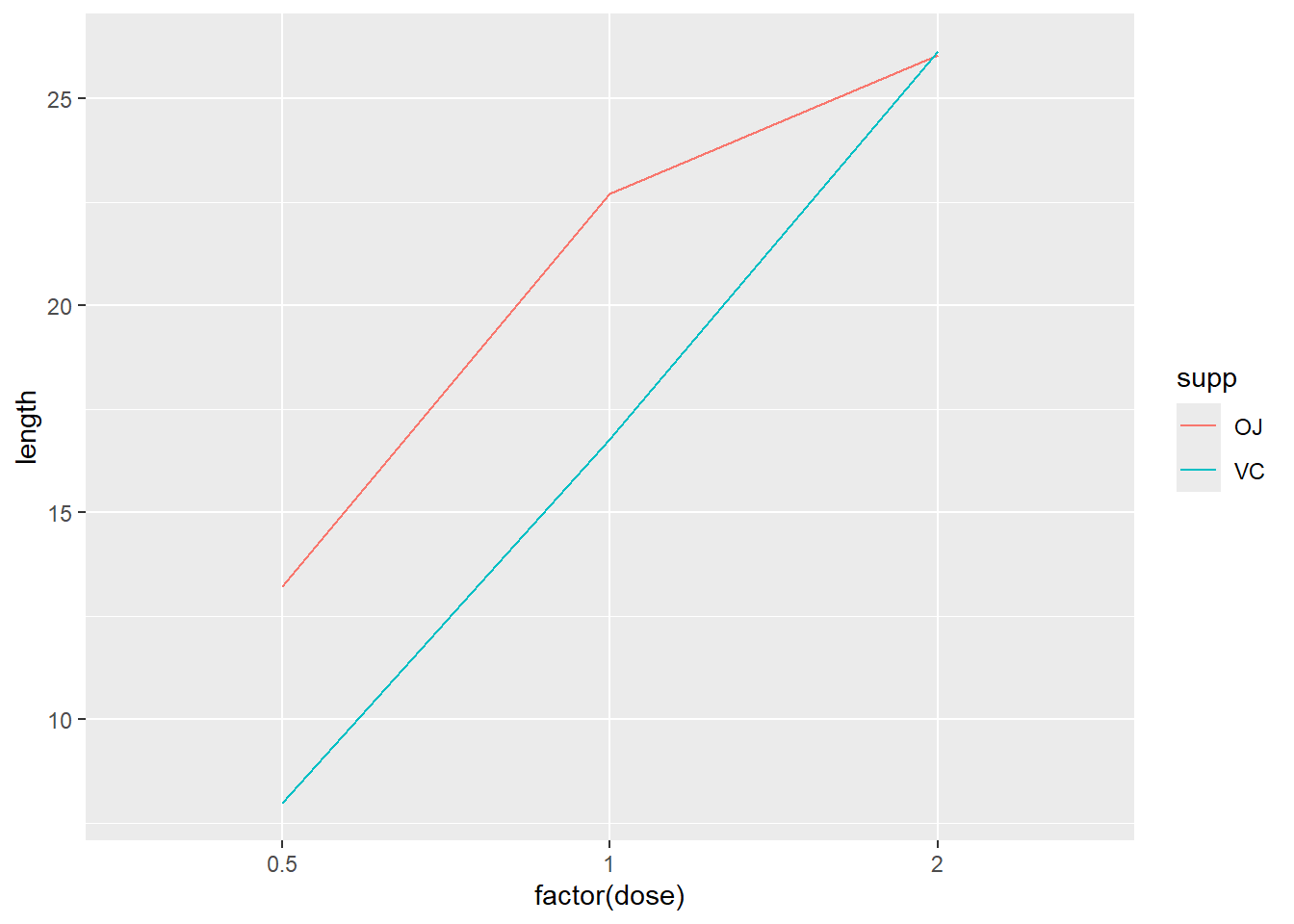
除了分别设定一个映射到 x 和 y 的变量,再将另一个(离散)变量映射到颜色(colour)或者线性(linetype)即可:
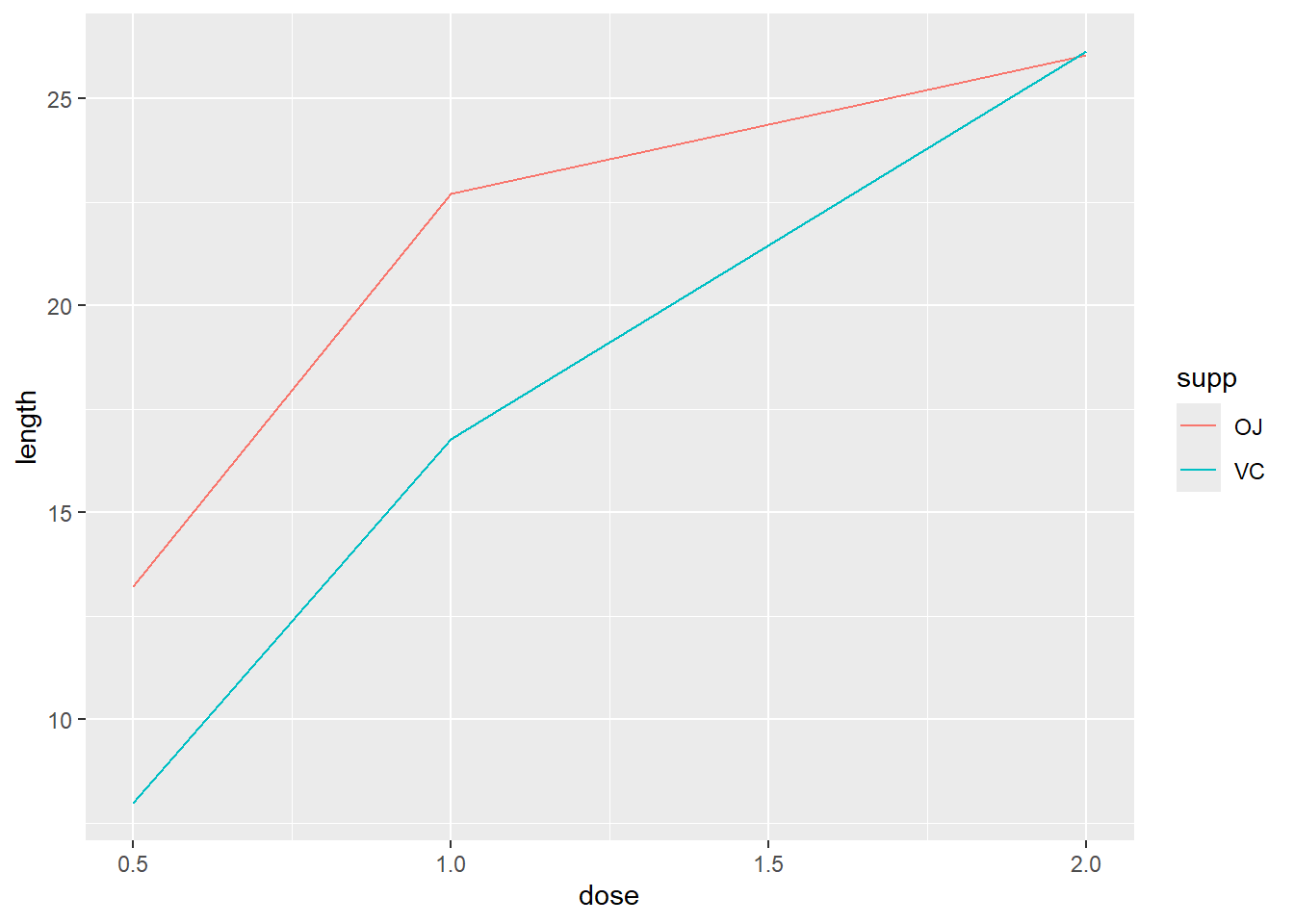
tg 数据集共有三列,其中一列正是我们映射到 colour 和 linetype 的 supp 因子(离散型变量),而将 dose 作为 x 轴,length 作为 y 轴(连续型变量)。
折线图的 X 轴既可以对应于连续变量也可以对应于分类变量。
有时候,映射到 X 的变量虽然被存储为数值型变量,但被看做分类变量来处理。
在上述的 tg 数据集中,dose 有三个取值:0.5、1.0和2.0。
或许用户更想将其当做分类变量而不是连续变量来处理,那么运行 factor() 函数将其转换为因子型变量。
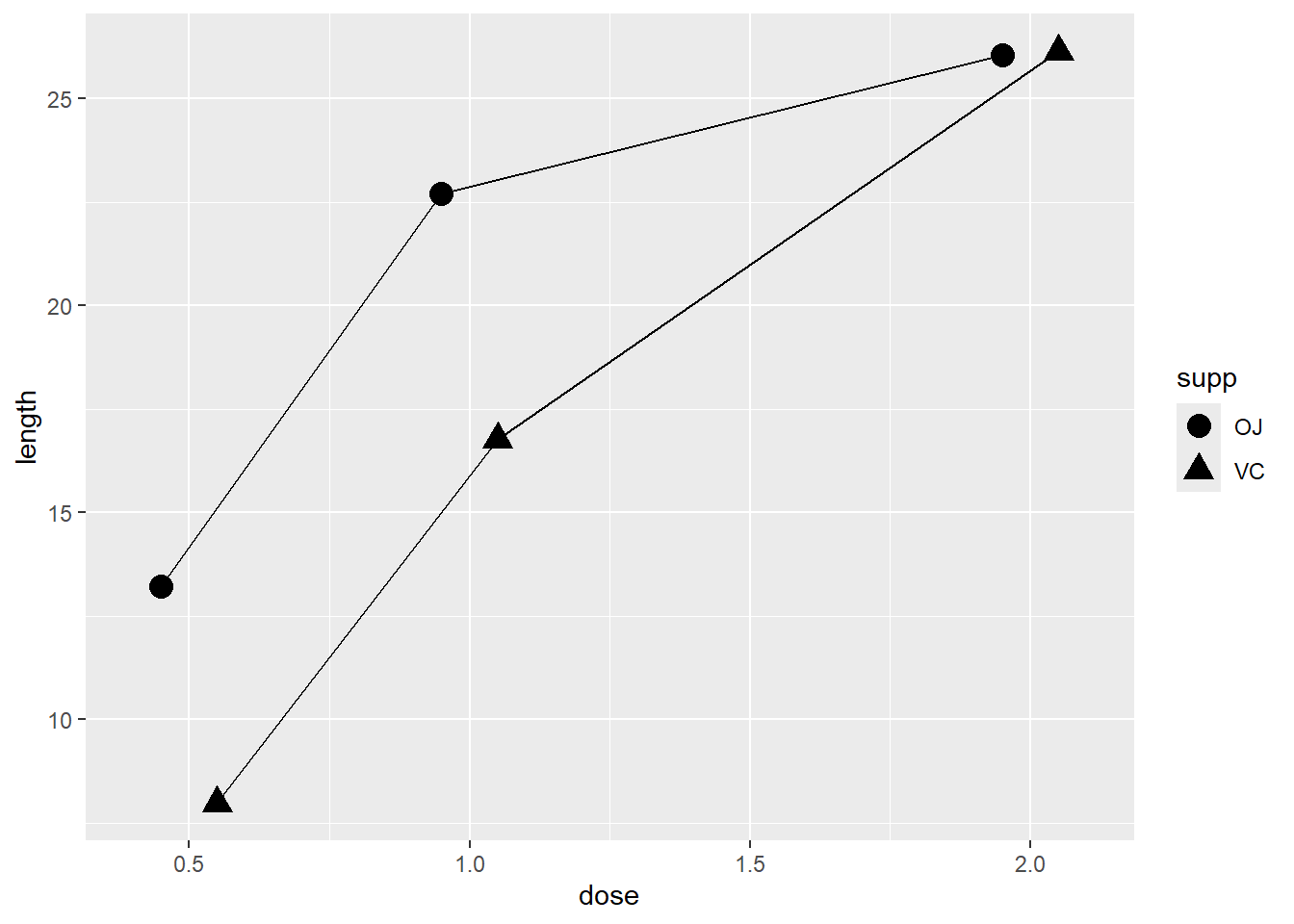
如果折线图上有数据标记,你也可以将分组变量映射到数据标记的属性,如 shape 和 fill 等。
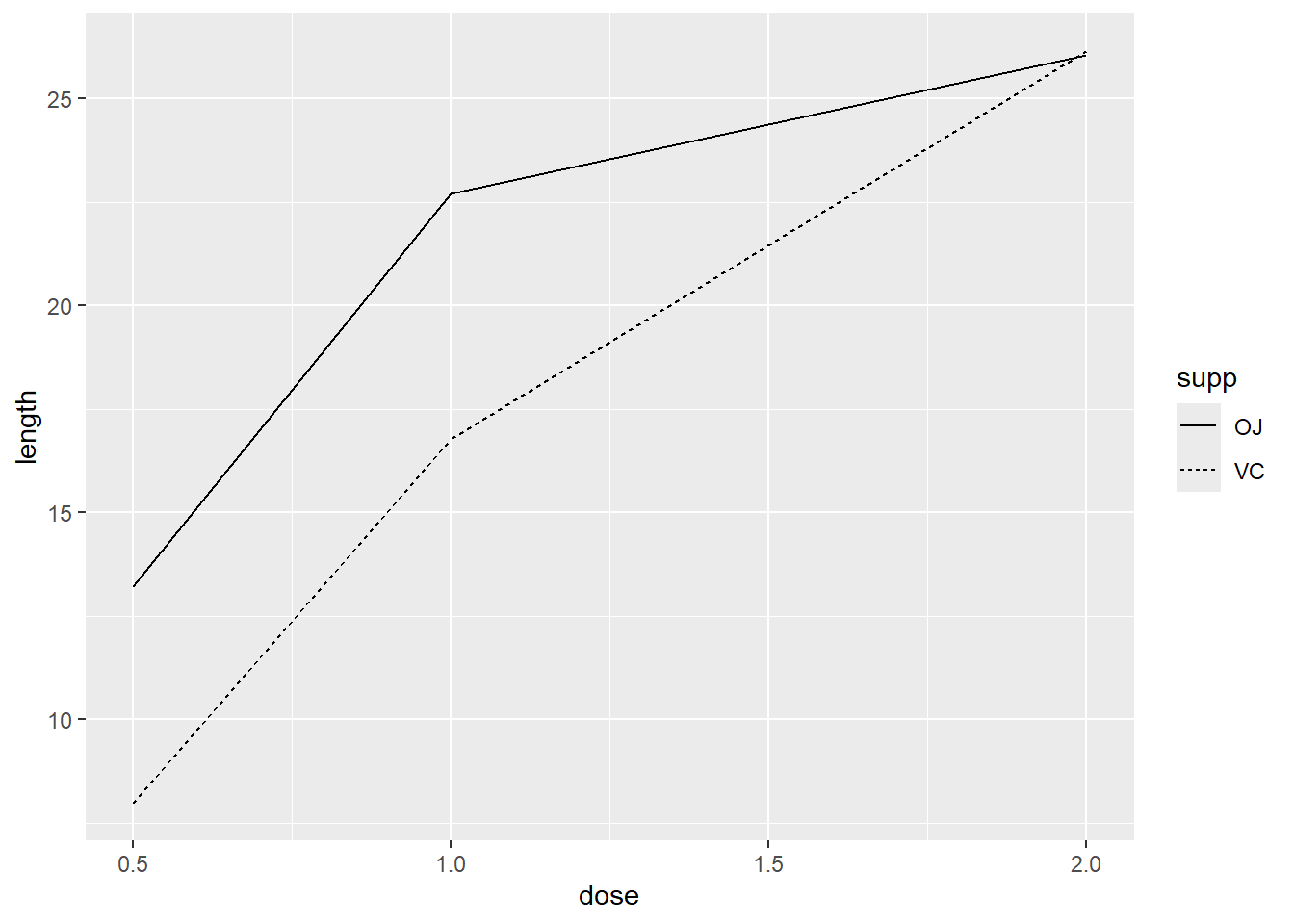
通过设置线型(linetype)、线宽(linewidth)和颜色(colour或color)参数可以分别修改折线的线性(实线、虚线、点线等),线宽(单位为毫米)和颜色。
将上述参数的值传递给 geom_line() 函数可以设置折线图的对应属性。
对于多重折线图而言,设定图形属性会对图上的所有折线产生影响。
而将变量映射到图形属性则会使图上的每条折线具有不同的外观。
折线图默认颜色并不是很吸引眼球,所以用户可以使用其他调色板1着色,可以调用 scale_colour_brewer() 函数和 scale_colour_manual 函数实线。
# load package
library(ggplot2)
# load dataset
library(gcookbook)
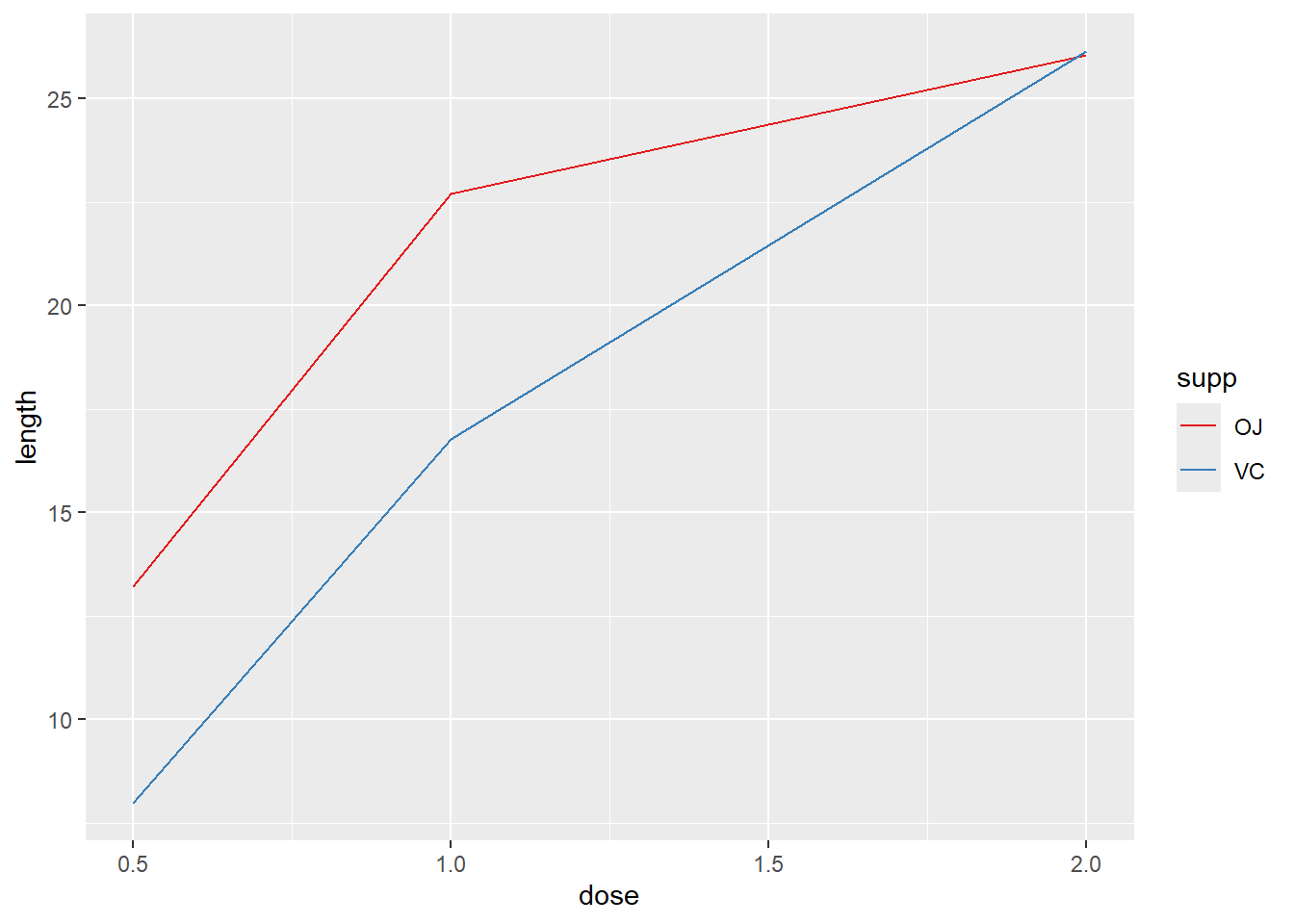
# 如果两条折线的图形属性相同,需要指定一个分组变量
ggplot(tg,aes(x = dose,y = length, group = supp))+
geom_line(colour = "darkgreen",size = 1.5)
# 因为变量 supp 被映射到了颜色(colour)属性,所以它自动作为分组变量
ggplot(tg,aes(x = dose,y = length, colour = supp))+
geom_line(linetype = "dashed")+
geom_point(shape = 22,size = 3,fill = "white")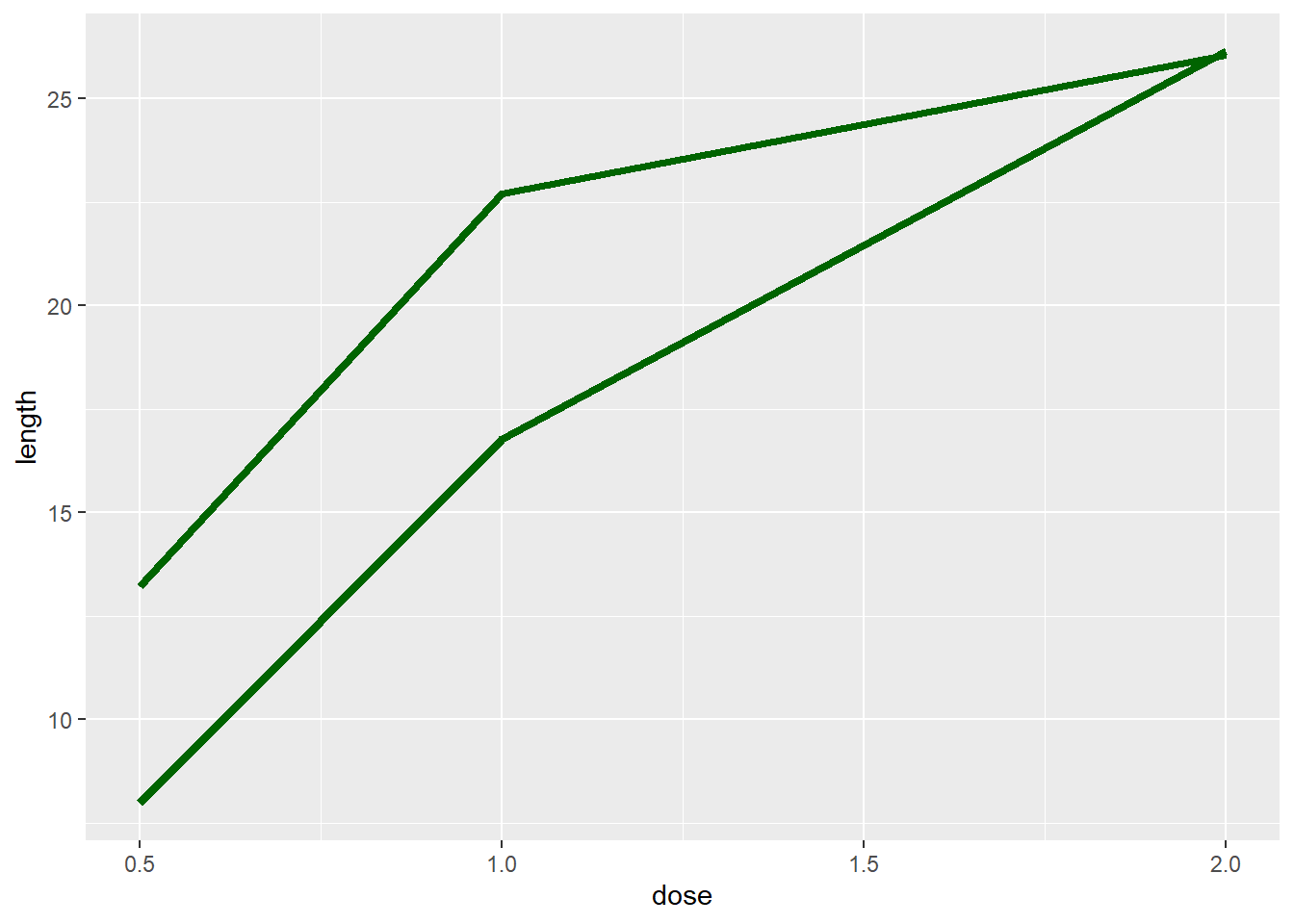
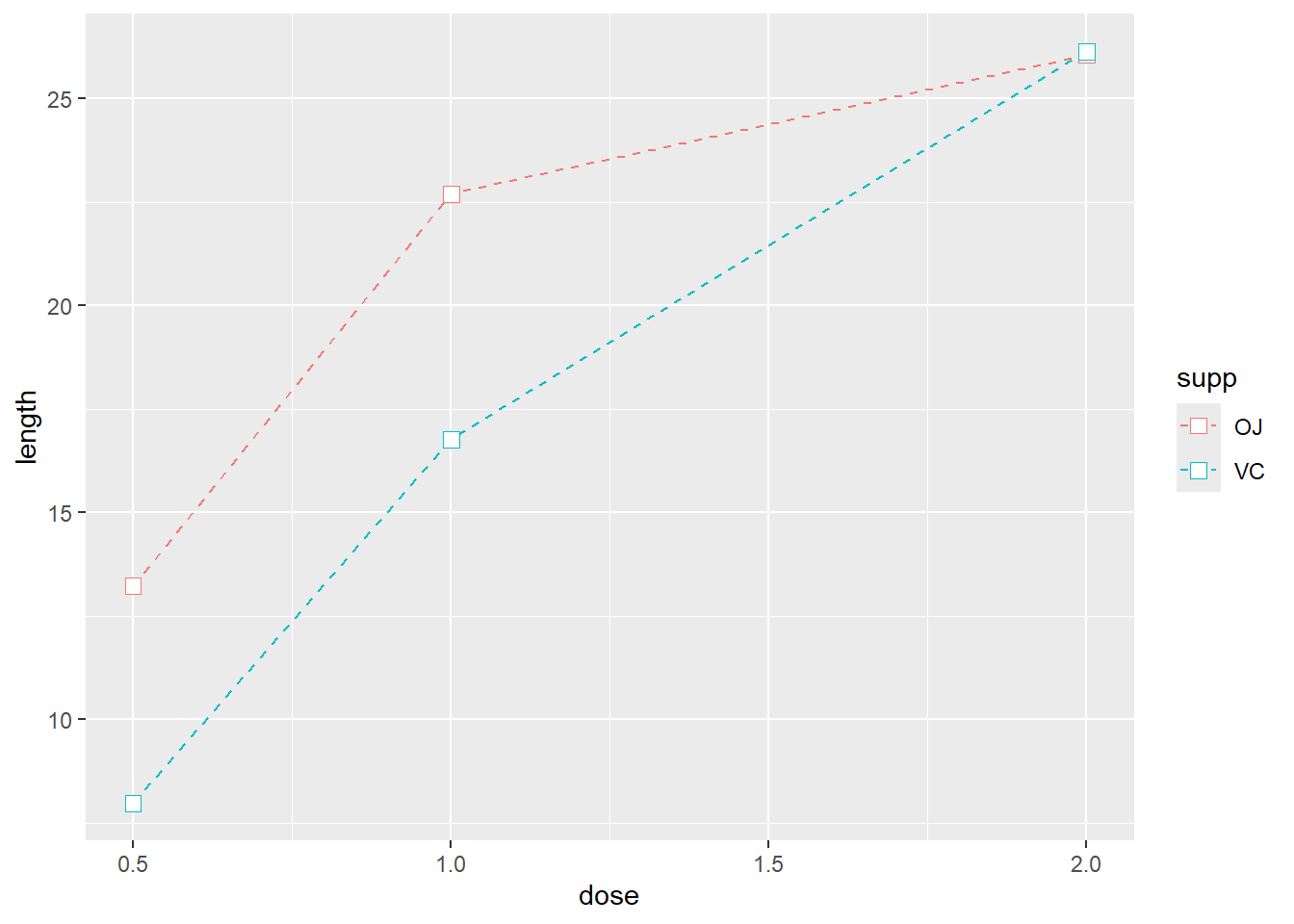
在函数 aes() 外部设定函数 geom_point() 的参数 size(大小)、shape(形状)、colour(颜色)和 fill(填充色)即可。
The default shape for points is a solid circle, the default size is 2, and the default colour is black.The fill color is relevant only for some point shapes (numbered 21–25), which have separate outline and fill colors. The fill color is typically NA, or empty; you can fill it with white to get hollow-looking circles
如果要将数据标记和折线设定为不同的颜色,用户必须折线绘制完成后再设定数据标记的颜色,此时,数据标记被绘制在更上面的图层,以避免被折线遮盖。
这里定义了一个函数 pd = position_dodge(0.2) 来将图形错开,原始用法可参照 图 11。
# load package
library(ggplot2)
library(gcookbook) # Load gcookbook for the tg data set
# Save the position_dodge specification because we'll use it multiple times
pd <- position_dodge(0.2)
ggplot(tg, aes(x = dose, y = length, fill = supp)) +
geom_line(position = pd) +
geom_point(shape = 21, size = 3, position = pd) +
scale_fill_manual(values = c("black","white"))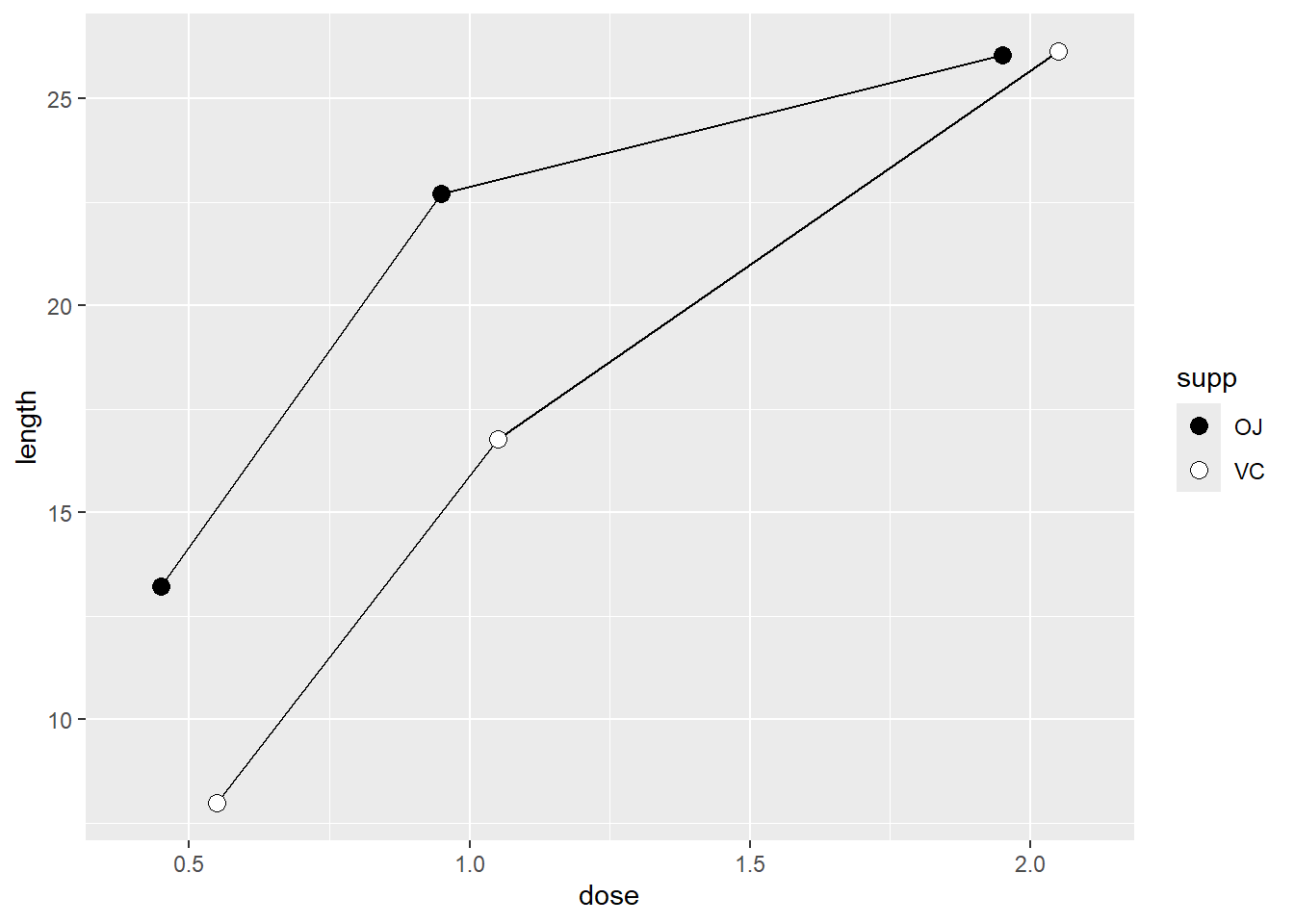
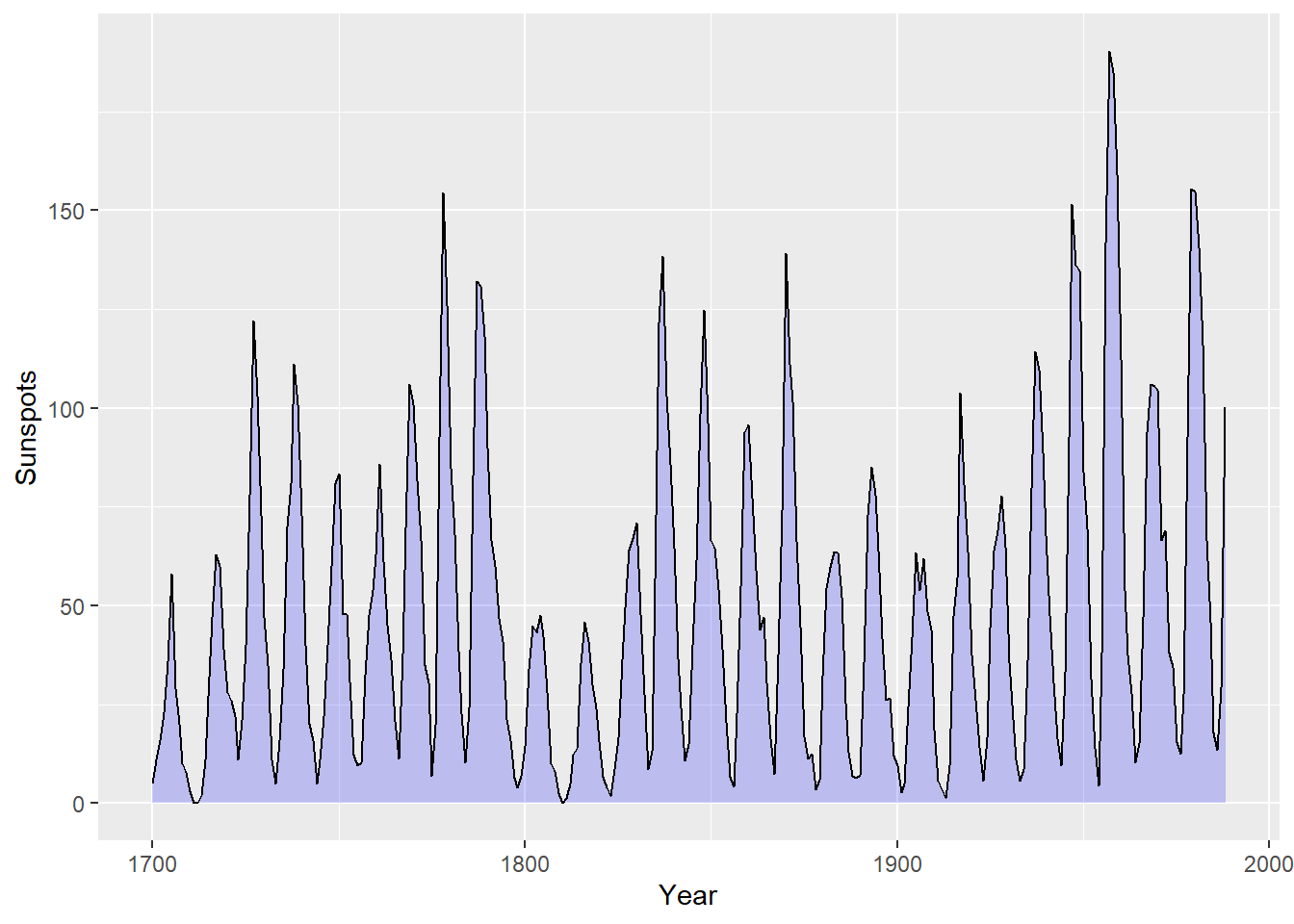
运行 geom_area() 函数即可绘制面积图。
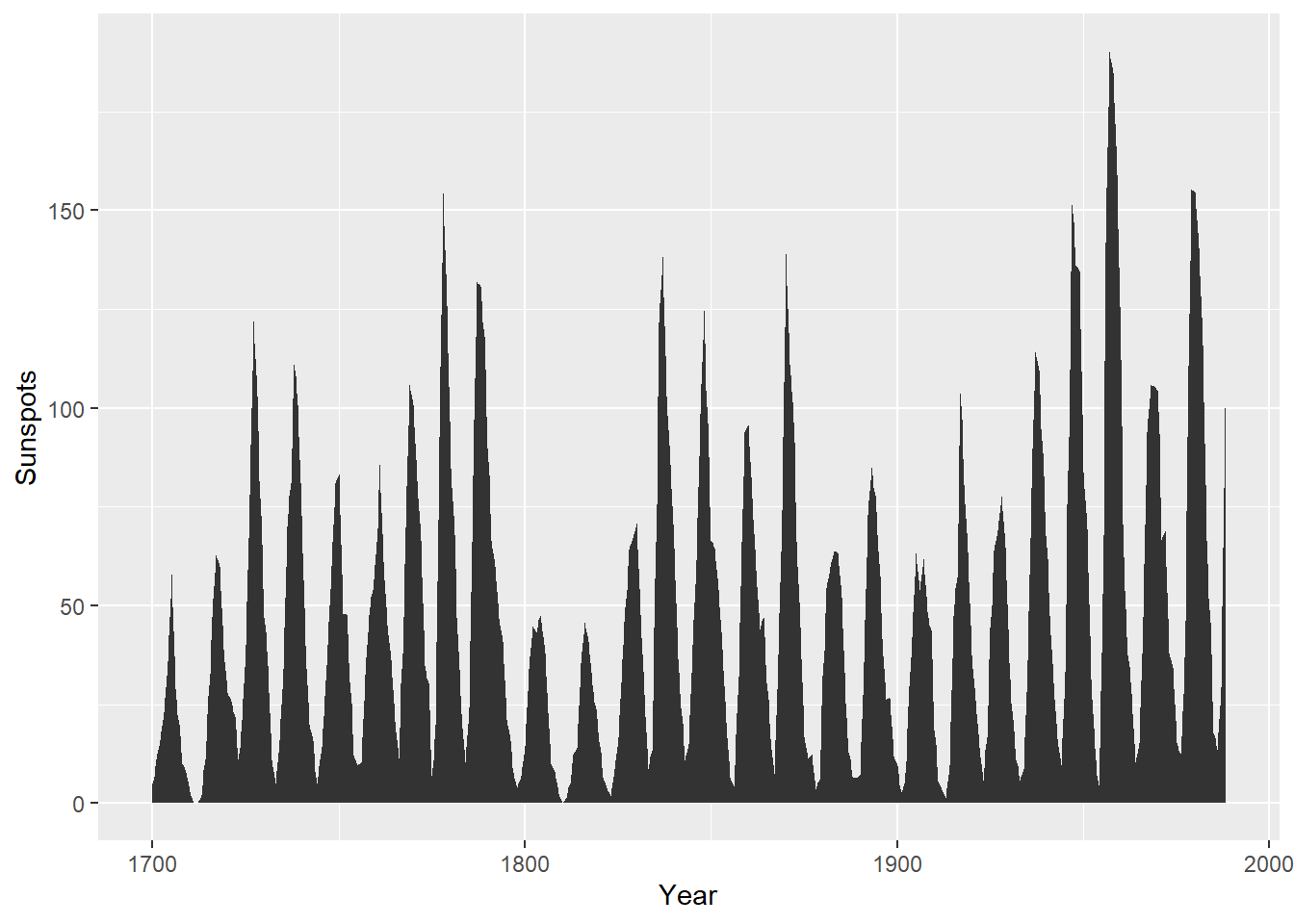
默认情况下,面积图的填充色都是黑灰色且没有边框线,通过设定 fill 可以修改面积图的填充色。
下图 图 20 将把填充色设定为蓝色,并通过 alpha=0.2 将面积图的透明度设定为 80% ,另外,用户可以看到面积图的网格线,通过设置 colour 为面积图添加边框线。
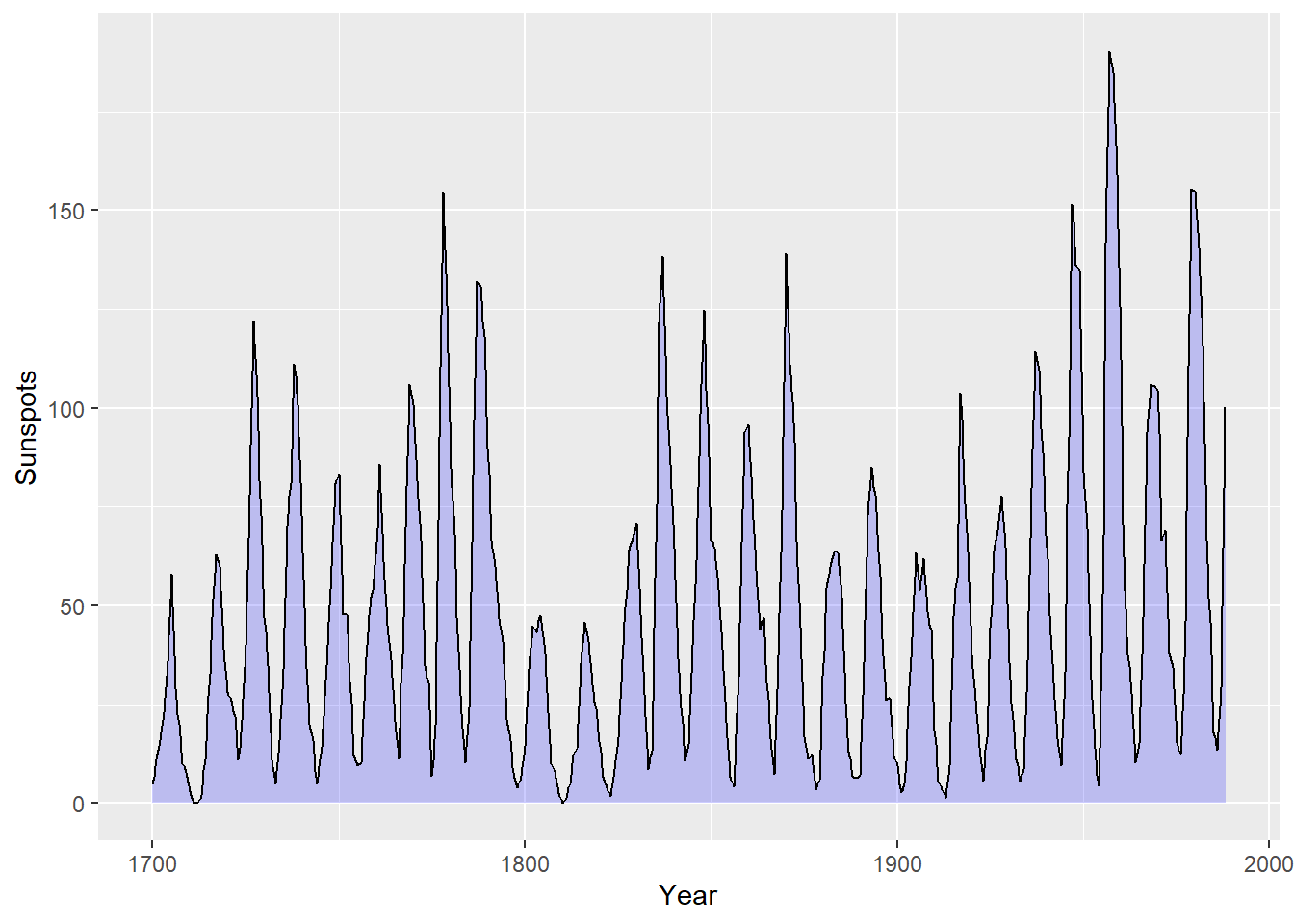
给整个面积图添加边框线后的效果可能并不十分令人满意,因为此时系统会在面积图的起点和终点位置分别绘制一条垂直线,且在底部绘制一条横线。
为了避免上述情况,可以先绘制不带框线的面积图(不设定 colour),然后添加图层,并用 geom_line() 函数绘制轨迹线,如下图 图 21 。
依旧是运行 geom_area() 函数,但是需要映射一个因子型变量到 fill 即可,如下图 图 22 所示。
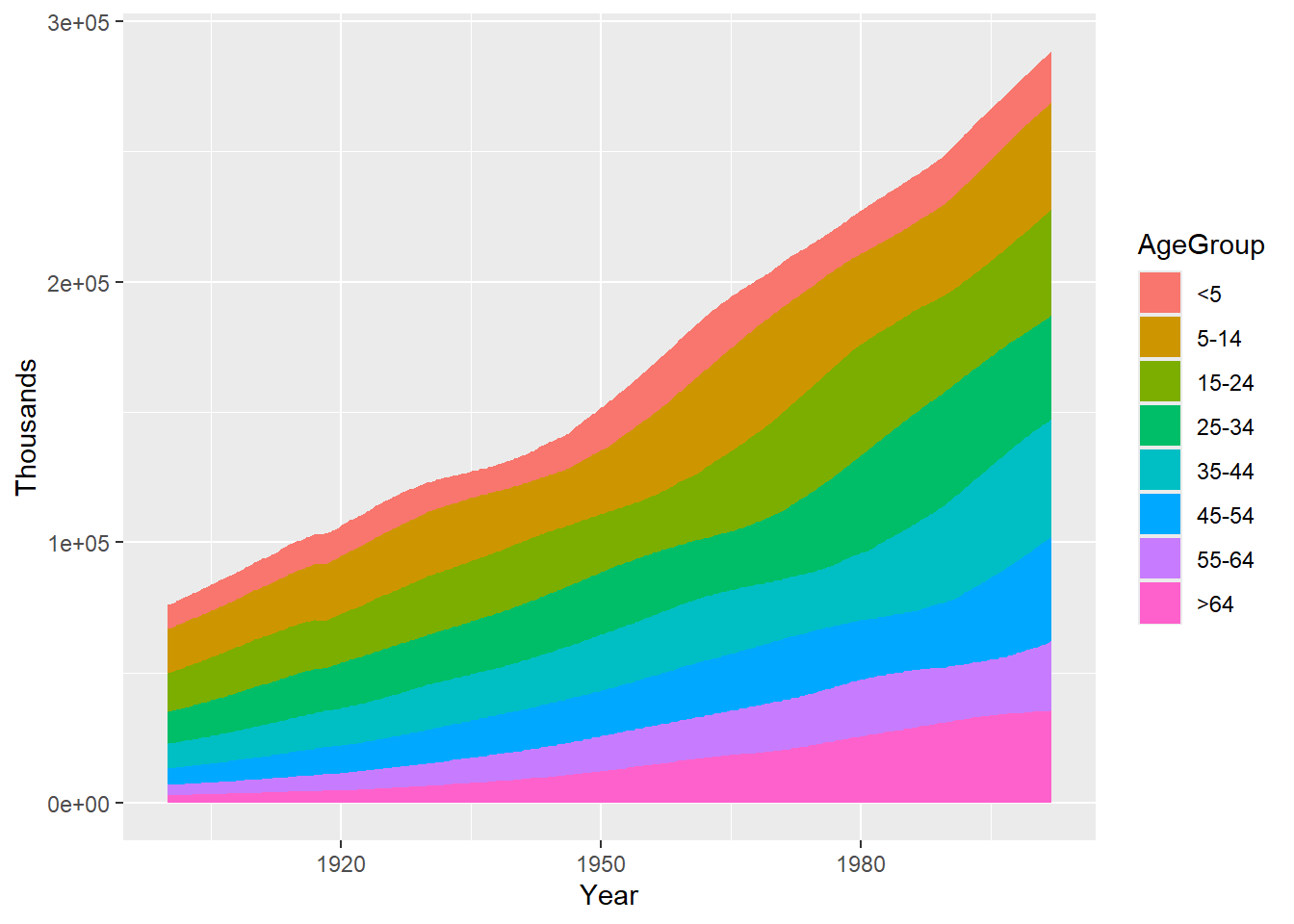
堆积面积图对应的基础数据通常为宽格式(wide format),但 ggplot 要求数据必须是长格式(long format),两种格式之间需要进行转换。2
将 图 22 的调色板设定为蓝色渐变色,并在各个区域之间添加细线(size = .2),同时我们将填充区域设定为半透明(alpha = .4 ),这样可以透过填充区域看见网格线。
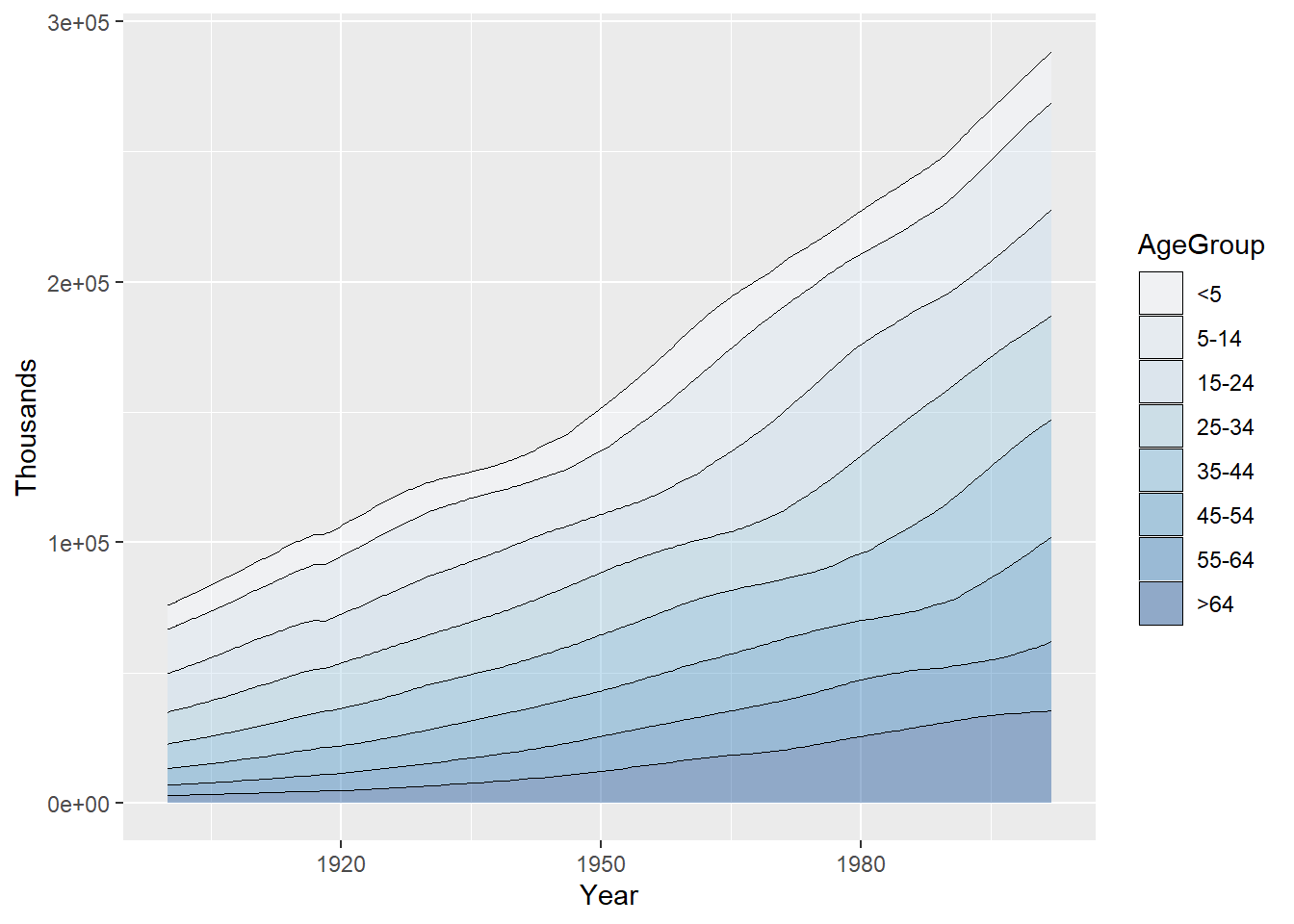
因为堆积面积图中的各个部分是由多边形构成的,所以其具有左、右边框线,这样的绘图效果不尽人意且可能产生误导效果。
下图将绘制一个不带边框线的堆积面积图:
# load package
library(ggplot2)
library(gcookbook) # Load gcookbook for the uspopage data set
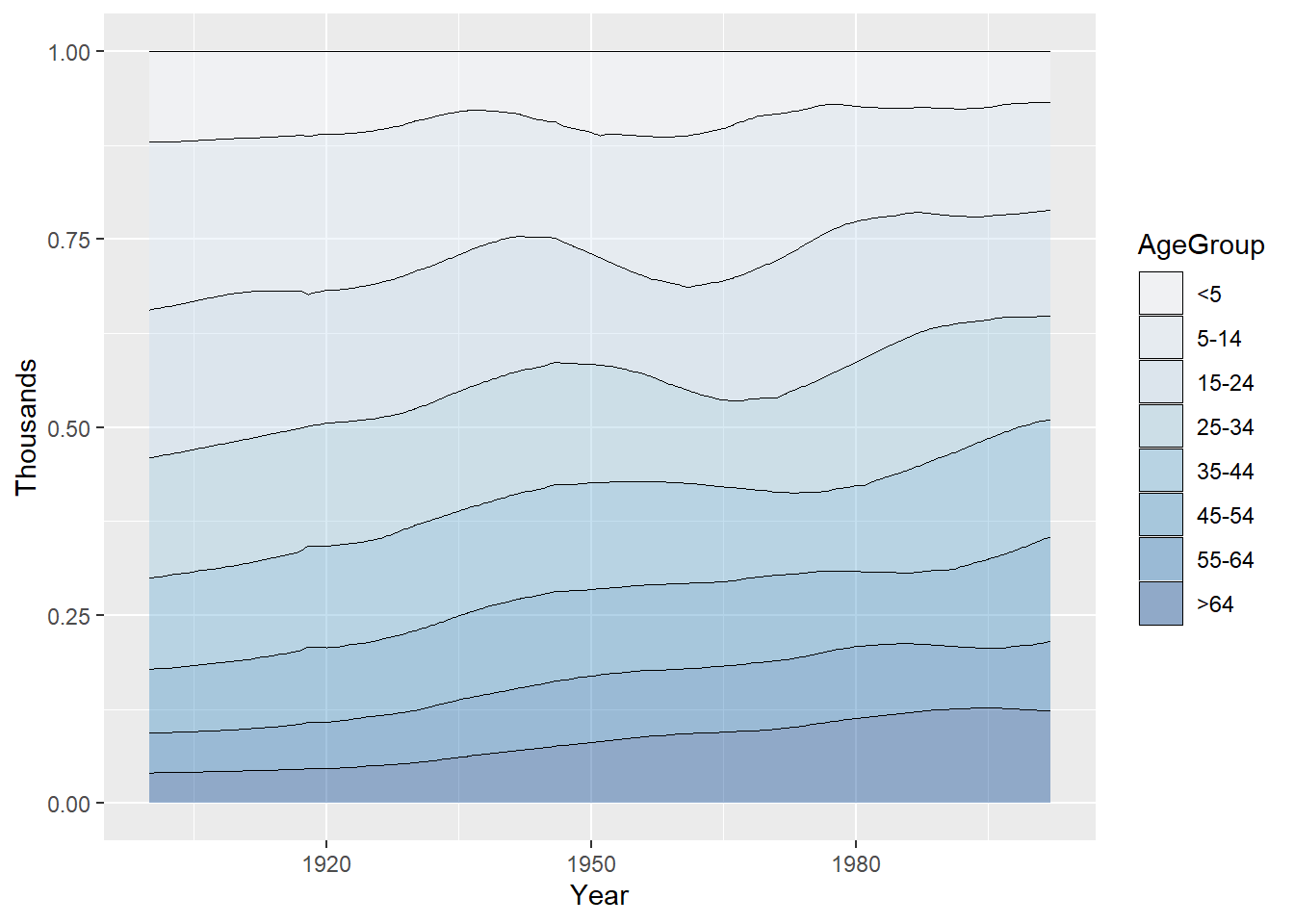
ggplot(uspopage, aes(x = Year, y = Thousands, fill = AgeGroup, order = dplyr::desc(AgeGroup))) +
geom_area(colour = NA, alpha = .4) +
scale_fill_brewer(palette = "Blues") +
geom_line(position = "stack", size = .2)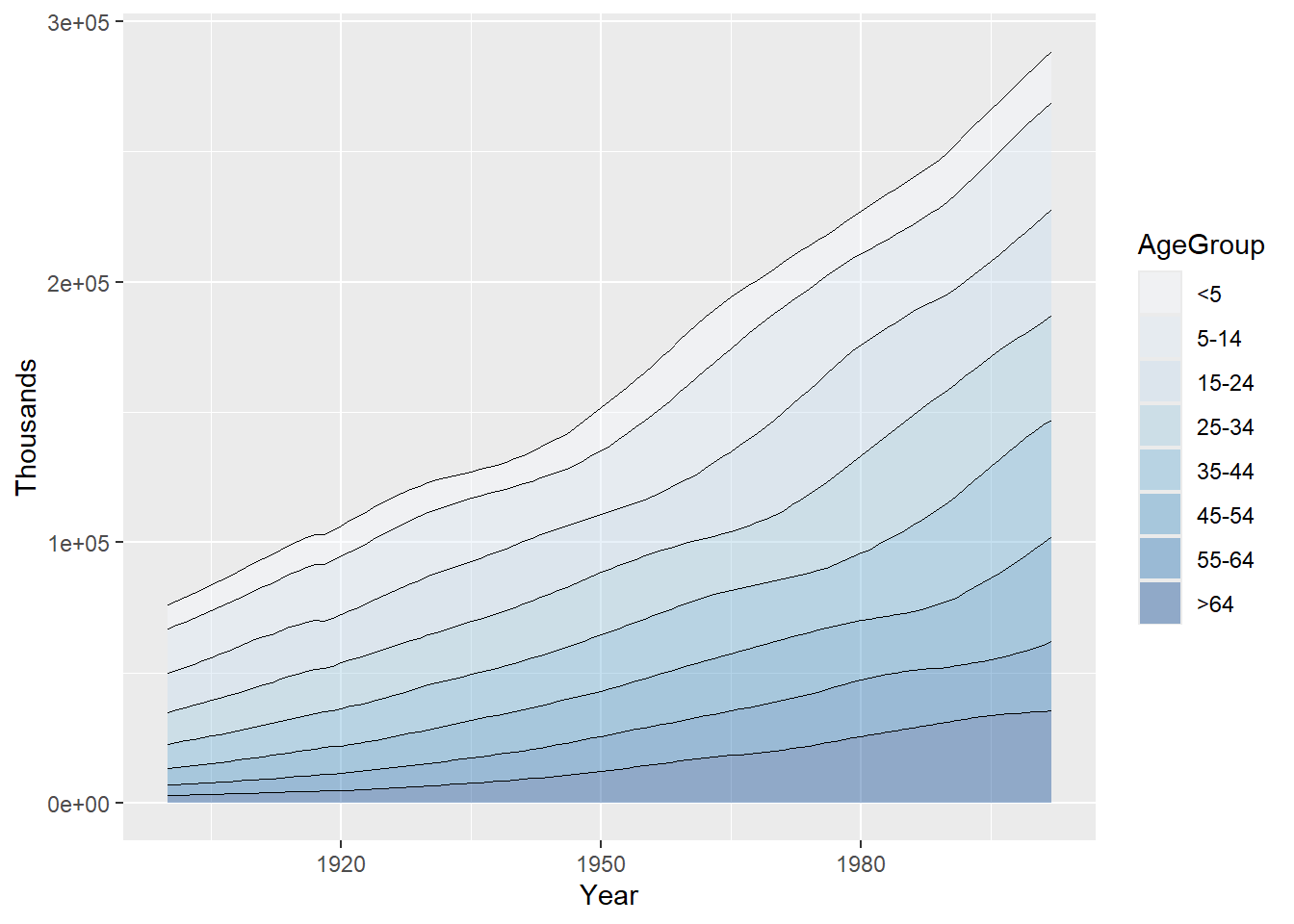
使用 geom_area(position = "fill") 函数实现这一效果:
带百分比标签的百分比堆积面积图,通过运行 position = "fill" 可将 y 值的范围按比例调整为 0-1。
再运行 scale_y_continuous(labels = scales::percent) 可输出百分比标签。
# load package
library(ggplot2)
library(gcookbook) # Load gcookbook for the uspopage data set
ggplot(uspopage, aes(x = Year, y = Thousands, fill = AgeGroup)) +
geom_area(position = "fill",colour = "black", size = .2, alpha = .4) +
scale_fill_brewer(palette = "Blues")+
scale_y_continuous(labels = scales::percent)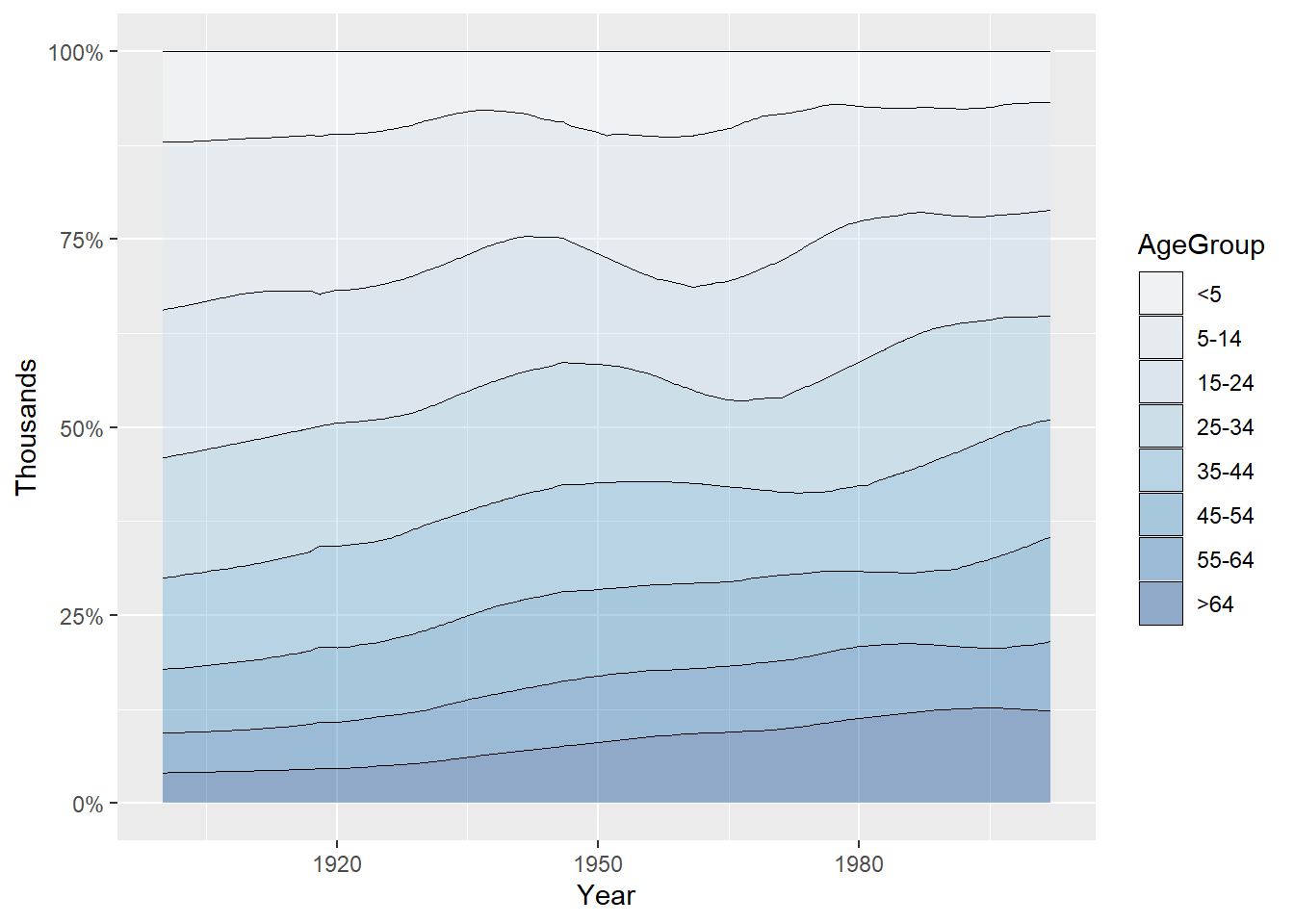
使用 geom_ribbon() 函数,然后分别映射一个变量到 ymin 和 ymax 即可。
这里使用的数据集为 climate 数据集,其中 Anomaly10y 变量表示了各年温度相对于 1950~1980 年平均水平偏差(以摄氏度衡量)的 10 年移动平均。变量 Unc10y 表示其 95% 置信水平下的置信区间。
这里设定 ymax 和 ymin 分别等于Anomaly10y+Unc10y 和 Anomaly10y-Unc10y
Year Anomaly10y Unc10y
1 1800 -0.435 0.505
2 1801 -0.453 0.493
3 1802 -0.460 0.486
4 1803 -0.493 0.489
5 1804 -0.536 0.483
6 1805 -0.541 0.475#> Year Anomaly10y Unc10y
#> 1 1800 -0.435 0.505
#> 2 1801 -0.453 0.493
#> 3 1802 -0.460 0.486
#> ...<199 more rows>...
#> 203 2002 0.856 0.028
#> 204 2003 0.869 0.028
#> 205 2004 0.884 0.029
# Shaded region
ggplot(climate_mod, aes(x = Year, y = Anomaly10y)) +
geom_ribbon(aes(ymin = Anomaly10y - Unc10y, ymax = Anomaly10y + Unc10y), alpha = 0.2) +
geom_line()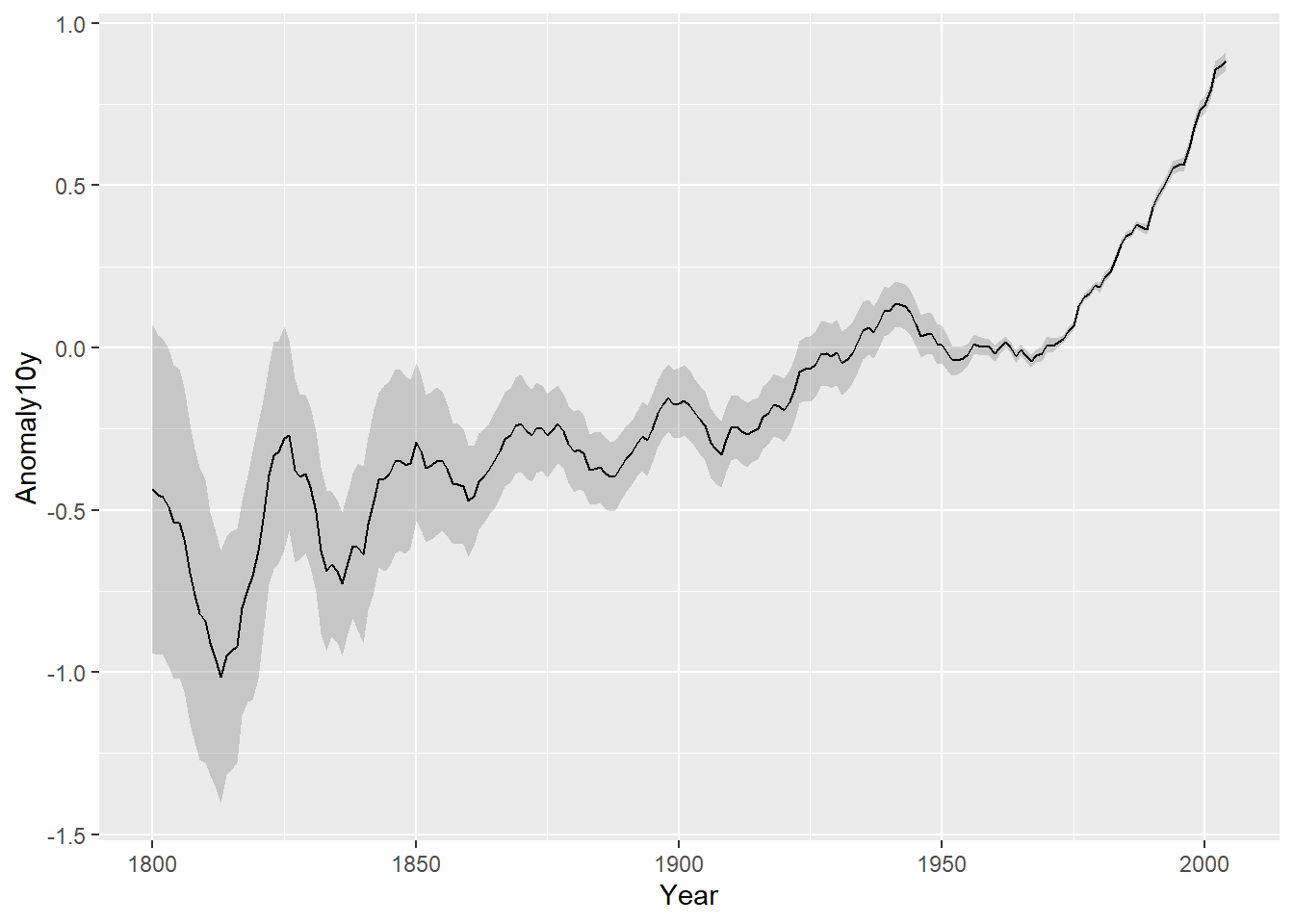
阴影部分的颜色实际上是黑灰色,但是看起来几乎是半透明的,这是因为通过设定 alpha = 0.2 将阴影部分的透明度设置为 80%。
需要注意的是,如果使用这种带阴影或颜色的置信域,应该将 geom_line() 函数放在 geom_ribbon() 之后,这样折线会被绘制在阴影区域上面的图层,如果反转顺序的话,阴影区域的颜色有可能使折线模糊不清。
但是用户可以选择使用虚线来表示置信域的上下边界,这样就不用考虑色域的问题,如下图 图 28 所示。
# load package
library(ggplot2)
library(gcookbook) # Load gcookbook for the climate data set
library(dplyr)
# With a dotted line for upper and lower bounds
ggplot(climate_mod, aes(x = Year, y = Anomaly10y)) +
geom_line(aes(y = Anomaly10y - Unc10y), colour = "grey50", linetype = "dotted") +
geom_line(aes(y = Anomaly10y + Unc10y), colour = "grey50", linetype = "dotted") +
geom_line()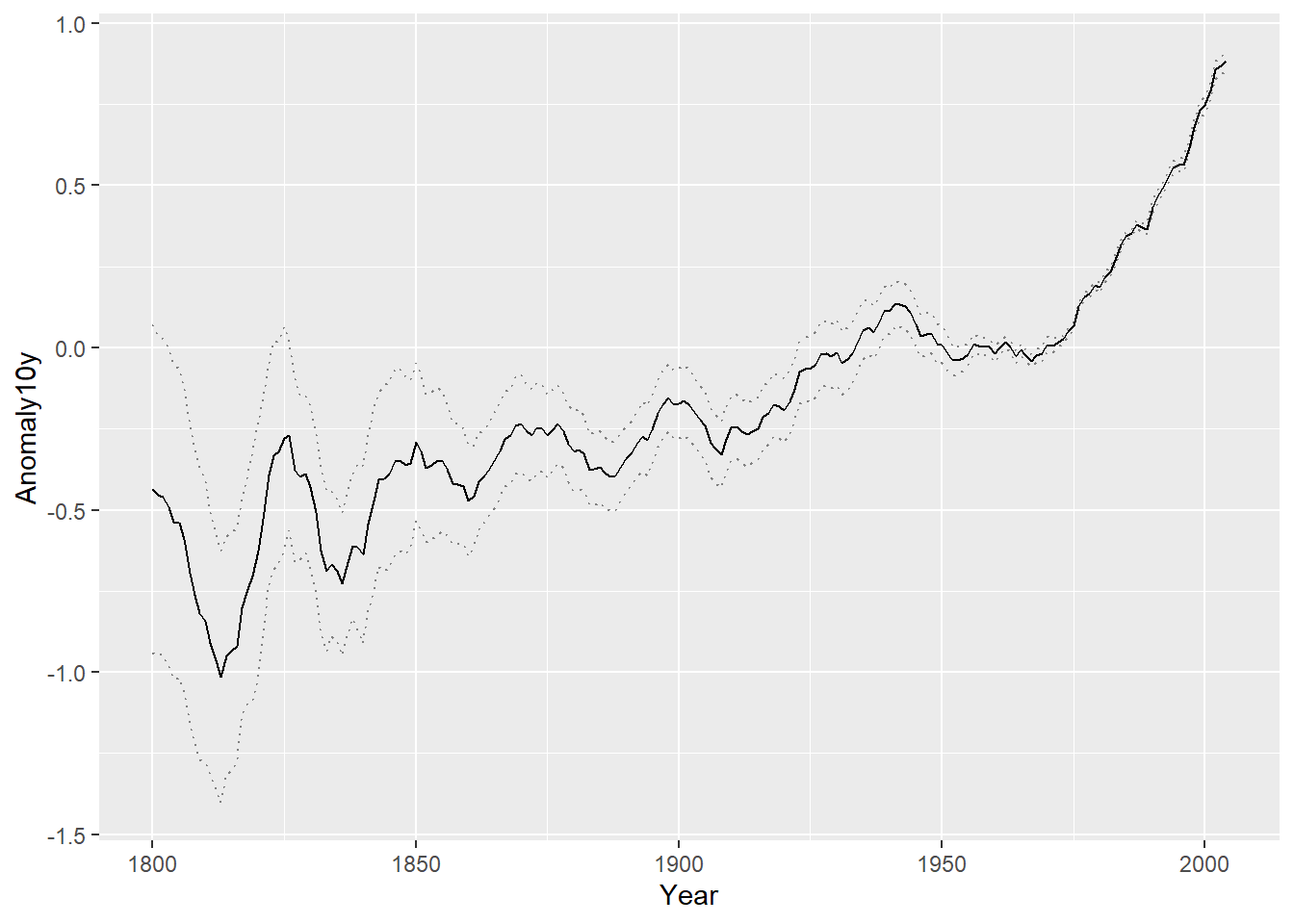
end.
ggplot2 本身内置了一些默认的调色板,但它也高度集成了其他 R 包和颜色系统的调色板,以提供更丰富的选择:
R 语言内置颜色: ggplot2 可以直接使用 R 语言中预定义的颜色名称(例如 “red”, “blue”)或十六进制颜色代码(例如 “#FF0000”)。
ColorBrewer: 这是一个非常流行的调色板集合,由地理学家 Cynthia Brewer 开发,主要用于地图制作,但非常适用于各种数据可视化。ColorBrewer 的调色板设计考虑了色彩感知和色盲友好性,分为:
顺序型 (Sequential):适用于表示有序数据,从低到高渐变。
发散型 (Diverging):适用于表示有中间值的数据,例如正负值、同意/不同意等,颜色从中间值向两端发散。
定性型 (Qualitative):适用于表示分类数据,颜色之间没有内在顺序。 ggplot2 通过 scale_color_brewer() 和 scale_fill_brewer() 函数来使用 ColorBrewer 调色板。
viridis: 这是一组在 ggplot2 中非常受欢迎的调色板(包括 viridis, magma, inferno, plasma, cividis)。它们的主要特点是感知均匀性和色盲友好性。这意味着无论颜色如何变化,人眼对颜色变化的感知是均匀的,并且即使是色盲人士也能区分不同的颜色。ggplot2 通过 scale_color_viridis_d() / scale_fill_viridis_d() (离散型)和 scale_color_viridis_c() / scale_fill_viridis_c() (连续型)来使用这些调色板。
自定义调色板: 用户可以根据需要创建自己的调色板,通过 scale_color_manual() 和 scale_fill_manual() 函数手动指定颜色。
其他扩展包: 还有许多其他 R 包提供了针对 ggplot2 的调色板,例如 ggsci 包提供了受科学期刊、数据可视化库等启发的调色板。
功能
ggplot2 调色板的主要功能是将数据映射到视觉美学属性(特别是颜色和填充色),从而增强数据图表的可读性和信息传递效率。
区分数据类别: 当你的数据中有离散变量(分类数据)时,调色板会为每个类别分配不同的颜色,让观众能够轻松区分不同的组别。例如,在散点图中用不同颜色表示不同的物种。
表示数据强度/趋势: 对于连续变量,调色板通常使用颜色渐变来表示数值的大小或趋势。例如,颜色从浅到深表示数值从小到大。
突出数据特征: 通过选择合适的调色板,可以突出数据中的特定模式、异常值或重要区域。
提高图表美观度: 美观的颜色选择能够提升图表的整体视觉吸引力,使其更具专业性和易读性。
支持色盲友好: 许多调色板(如 viridis 和 ColorBrewer 的部分调色板)都经过设计,以确保色盲人士也能良好地区分颜色,从而提高图表的可访问性。
映射离散和连续数据。
在 ggplot2 中绘制堆积面积图时,确实需要将宽格式数据转换为长格式。这并不是 ggplot2 独有的要求,而是 “整洁数据”(Tidy Data) 原则在数据可视化中的体现。
为什么需要转换?
ggplot2 的设计哲学 (Grammar of Graphics)
ggplot2 基于 Leland Wilkinson 的 图形语法(Grammar of Graphics)。其核心思想是将图表分解为独立的组件:数据、几何对象(geoms)、统计变换(stats)、标度(scales)等。这种语法要求数据以特定的方式组织,以便它能直接映射到图表的视觉属性上。
映射(Mapping): 在 ggplot2 中,你需要明确地将数据变量映射到美学属性(如 x 轴、y 轴、颜色、填充、大小等)。
整洁数据: ggplot2 最适合处理整洁数据。整洁数据的定义是:
每个变量一列:数据集中的每个变量都应该有自己的一列。
每个观测值一行:每个观测值(或案例)都应该有自己的一行。
每个单元格一个值:每个单元格只包含一个值。
对于堆积面积图,如果你有宽格式数据,例如:
| 年份 | 产品A | 产品B | 产品C |
| 2020 | 100 | 50 | 20 |
| 2021 | 120 | 60 | 30 |
在这种格式下,“产品A”、“产品B”、“产品C” 都是独立的列。ggplot2 很难直接理解 “产品A”、“产品B”、“产品C” 应该被视为一个共同的“产品类型”变量,并且它们的数值应该被堆叠。
堆积图的要求
堆积图的本质是按照某个分类变量(在堆积面积图通常是类别或分组)来对数值变量进行累加。为了实现这一点,ggplot2 需要一个明确的列来表示“类别”(例如,“产品类型”),以及另一个明确的列来表示“值”(例如,“销售额”)。
当数据是长格式时:
| 年份 | 产品类型 | 销售额 |
| 2020 | 产品A | 100 |
| 2020 | 产品B | 50 |
| 2020 | 产品C | 20 |
| 2021 | 产品A | 120 |
| 2021 | 产品B | 60 |
| 2021 | 产品C | 30 |
现在,ggplot2 可以清晰地识别:
X 轴: 年份
Y 轴: 销售额
填充颜色(或分组): 产品类型
它知道如何根据 产品类型 对 销售额 进行堆积。
如何转换?
在 R 语言中,最常用的数据转换包是 tidyr,它是 tidyverse 生态系统的一部分。tidyr 包提供了 pivot_longer()(以前是 gather())函数,用于将宽格式数据转换为长格式。
假设我们有以下宽格式数据框 df_wide:
输出:
现在,我们使用 pivot_longer() 将其转换为长格式:
输出:
# A tibble: 9 × 3
Year ProductType Sales <dbl> <chr> <dbl>
1 2020 ProductA 100
2 2020 ProductB 50
3 2020 ProductC 20
4 2021 ProductA 120
5 2021 ProductB 60
6 2021 ProductC 30
7 2022 ProductA 150
8 2022 ProductB 70
9 2022 ProductC 40 使用长格式数据绘制堆积面积图
现在我们有了长格式数据 df_long,就可以轻松绘制堆积面积图了:
总结来说,将宽格式数据转换为长格式是 ggplot2 绘制堆积图的关键步骤。这不仅符合 ggplot2 的图形语法和整洁数据原则,也使得数据能够清晰地映射到图表的视觉属性上,从而正确地进行堆积和可视化。↩︎